業界トレンド
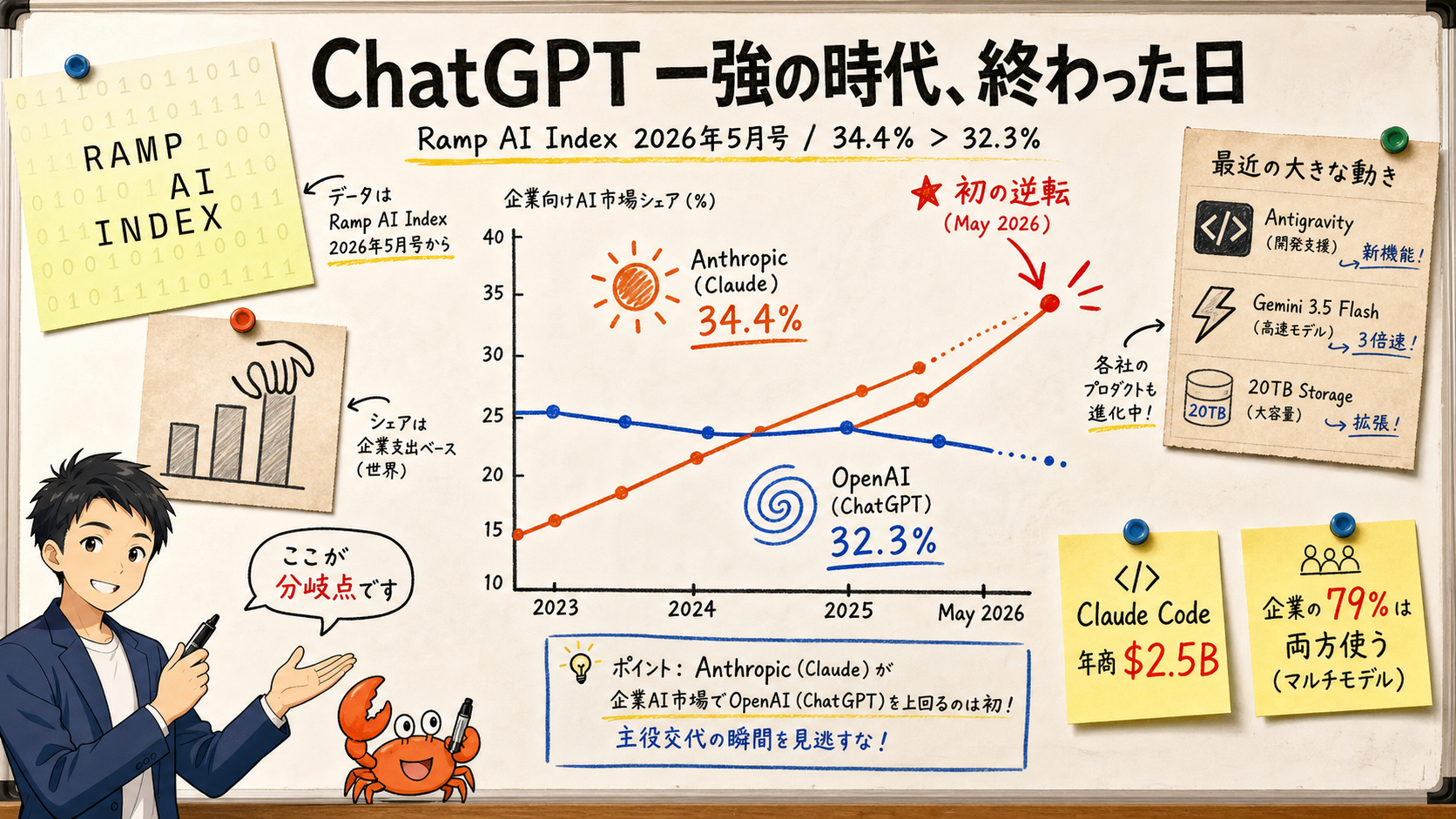
Anthropic が OpenAI を初めて逆転? 2026 年 5 月、企業 AI シェアで起きた『主役交代』を一般読者向けに整理
14 分
2026 年 5 月時点で Codex CLI 0.130.0 と Claude Code 2.1.143 はベンチごとに順位が入れ替わる時代。Terminal-Bench 2.0 / SWE-bench Verified / Aider Polyglot の公式・第三者集計、API 料金、CLI 機能差分、AI 営業自動化での使い分け基準を Sales Claw 視点で解説。

中澤 圭志
@keishi_nakazawaSales Claw 開発者

Key Facts
最新版
Codex CLI 0.130.0 (2026-05-08) / Claude Code 2.1.143 (2026-05-15)
既定モデル
GPT-5.5 (2026-04-23) / Claude Opus 4.7 (2026-04-16)
Terminal-Bench 2.0
vix + Opus 4.7 90.2% (1位) / Codex CLI + GPT-5.5 82.0% (7位)
API 料金 (入力/出力)
Opus 4.7 $5/$25 / GPT-5.5 $5/$30 / GPT-5.3-Codex $1.75/$14 per MTok
「Codex CLI と Claude Code はどっちが強いのか?2026 年 5 月時点の公式ベンチで横断的に比べたい。コストもタスク適性も含めて、現場で選べる基準が欲しい」—— 本記事ではこの疑問に対し、Terminal-Bench 2.0 公式リーダーボード・Aider Polyglot・SWE-bench Verified の集計、Anthropic / OpenAI 公式 Docs と GitHub Releases を一次情報として、AI 営業自動化に組み込む現場視点から答えます。
2026 年 5 月時点で、両者の最新版は Codex CLI 0.130.0 (2026-05-08 リリース) と Claude Code 2.1.143 (2026-05-15 リリース) です。背後のフラッグシップモデルは GPT-5.5 (2026-04-23 ロールアウト) と Claude Opus 4.7 (2026-04-16 リリース)。ベンチマーク上の優劣は「どの軸で見るか」で逆転するため、単純な勝ち負けではなく 「タスクごとの適性」 で読むのが現実的です。
本記事は OpenAI Codex 公式 Changelog / Claude Code 公式 Changelog / Anthropic Newsroom / Terminal-Bench 公式リーダーボード (tbench.ai) / Aider 公式ドキュメント / Claude / OpenAI 公式 Pricing ページ を一次情報として参照しています。記事公開時点で確認できる公式情報のみを取り上げ、第三者集計を引用する場合は出典を明示します。
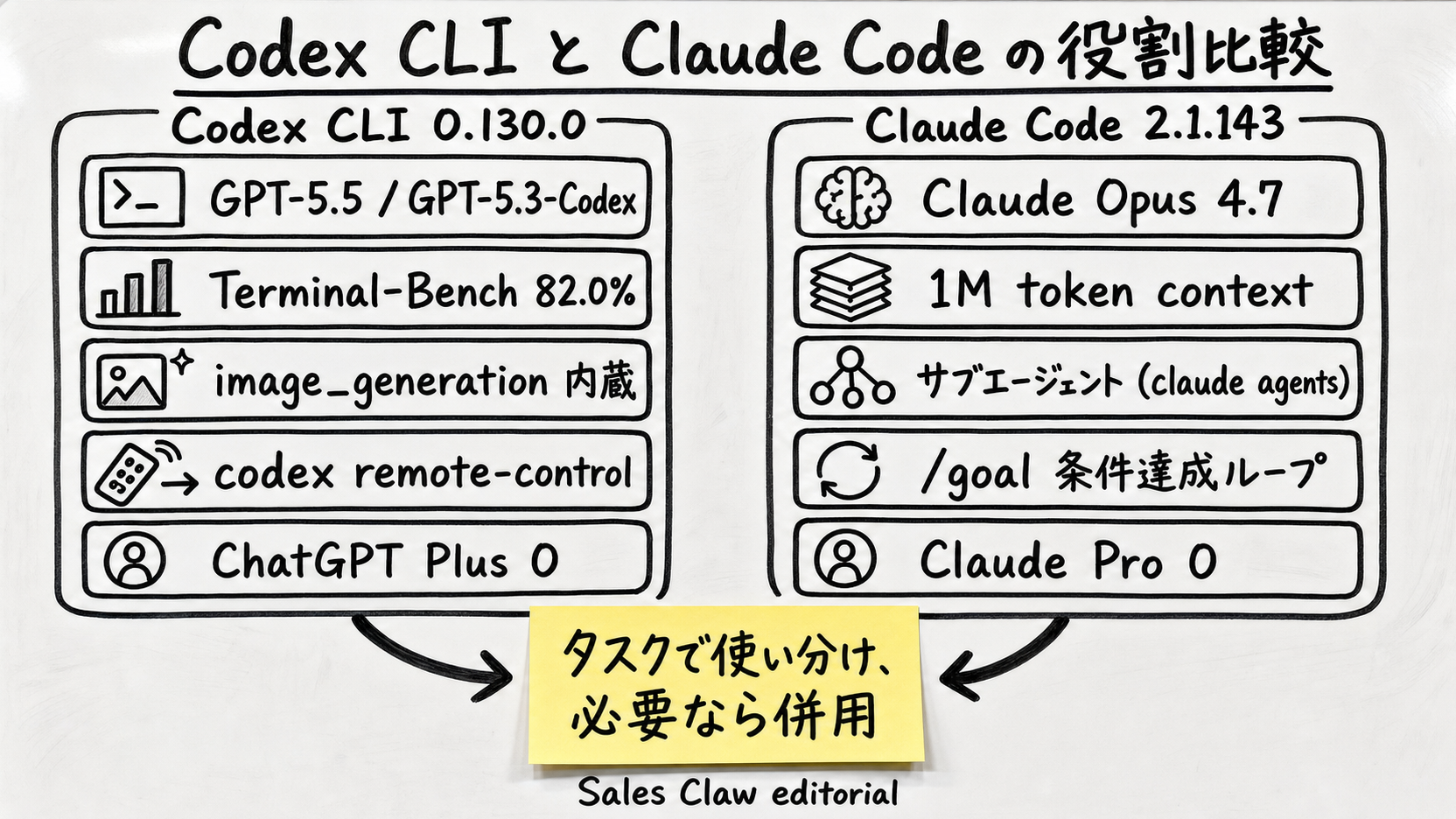
Codex CLI と Claude Code はどちらも「ターミナルから AI に指示を出してファイル編集・コード生成・コマンド実行をさせる」エージェント CLI ですが、起源と設計思想は異なります。
codex remote-control で外部プロセスから完全プログラム制御できる。画像生成 (gpt-image-2) を内蔵@openai/codex on npm、codex コマンドで起動xhigh effort level / Fast mode 対応claude agents)、/goal による条件達成ループ、/ultrareview、Plugin / Skill / MCP ファーストクラス。コンテキスト 1M token 標準@anthropic-ai/claude-code on npm、claude コマンドで起動コーディング・ターミナルタスク向けベンチマークは複数あり、それぞれ評価する能力が違います。本セクションでは Terminal-Bench 2.0 (公式)・SWE-bench Verified (第三者集計)・Aider Polyglot (公式) の 3 つを横断的に整理します。
tbench.ai の公式リーダーボード によると、2026-05-15 時点の上位 10 エントリは以下の通りです。
| Rank | エージェント | モデル | スコア | 日付 |
|---|---|---|---|---|
| 1 | vix | Claude Opus 4.7 | 90.2% ± 2.1 | 2026-05-15 |
| 2 | JJAgent | Multiple | 87.1% ± 1.3 | 2026-05-15 |
| 3 | NexAU-AHE | GPT-5.5 | 84.7% ± 2.1 | 2026-05-14 |
| 4 | LemonHarness | Multiple | 84.5% ± 2.6 | 2026-05-14 |
| 5 | Capy | GPT-5.5 | 83.1% ± 2.1 | 2026-05-14 |
| 6 | Polaris | Multiple | 82.2% ± 2.8 | 2026-05-14 |
| 7 | Codex CLI | GPT-5.5 | 82.0% ± 2.2 | 2026-04-23 |
| 8 | ForgeCode | GPT-5.4 | 81.8% ± 2.0 | 2026-03-12 |
| 9 | WOZCODE | Claude Opus 4.7 | 80.2% ± 2.1 | 2026-05-14 |
| 10 | TongAgents | Gemini 3.1 Pro | 80.2% ± 2.6 | 2026-03-13 |
SWE-bench Verified は実在の GitHub Issue を解かせる重量級ベンチで、コーディングエージェント評価のデファクト指標です。OpenAI は 2026 年 2 月以降コンタミ懸念で自社報告を一時停止しており、現在は Epoch AI 等の第三者トラッカーが集計しています。

Anthropic は Opus 4.7 発表時に 「メモリゼーション (記憶混入) の疑いがある問題を除外しても、Opus 4.6 比の改善幅は維持される」 と明記しており、ベンチコンタミに対する透明性姿勢を強調しています (出典: Anthropic Newsroom — Claude Opus 4.7)。実数値は第三者集計に依存するため、本記事では 「±数%の誤差を含むベースライン」として扱います。
Aider 公式リーダーボード は C++ / Go / Java / JavaScript / Python / Rust 225 問の Exercism 問題セットで評価します。
ベンチスコアは数字での比較ができますが、現場で効くのは 「日常タスクで何が楽になるか」です。両 CLI の最新版で確認できる機能差分を整理します。
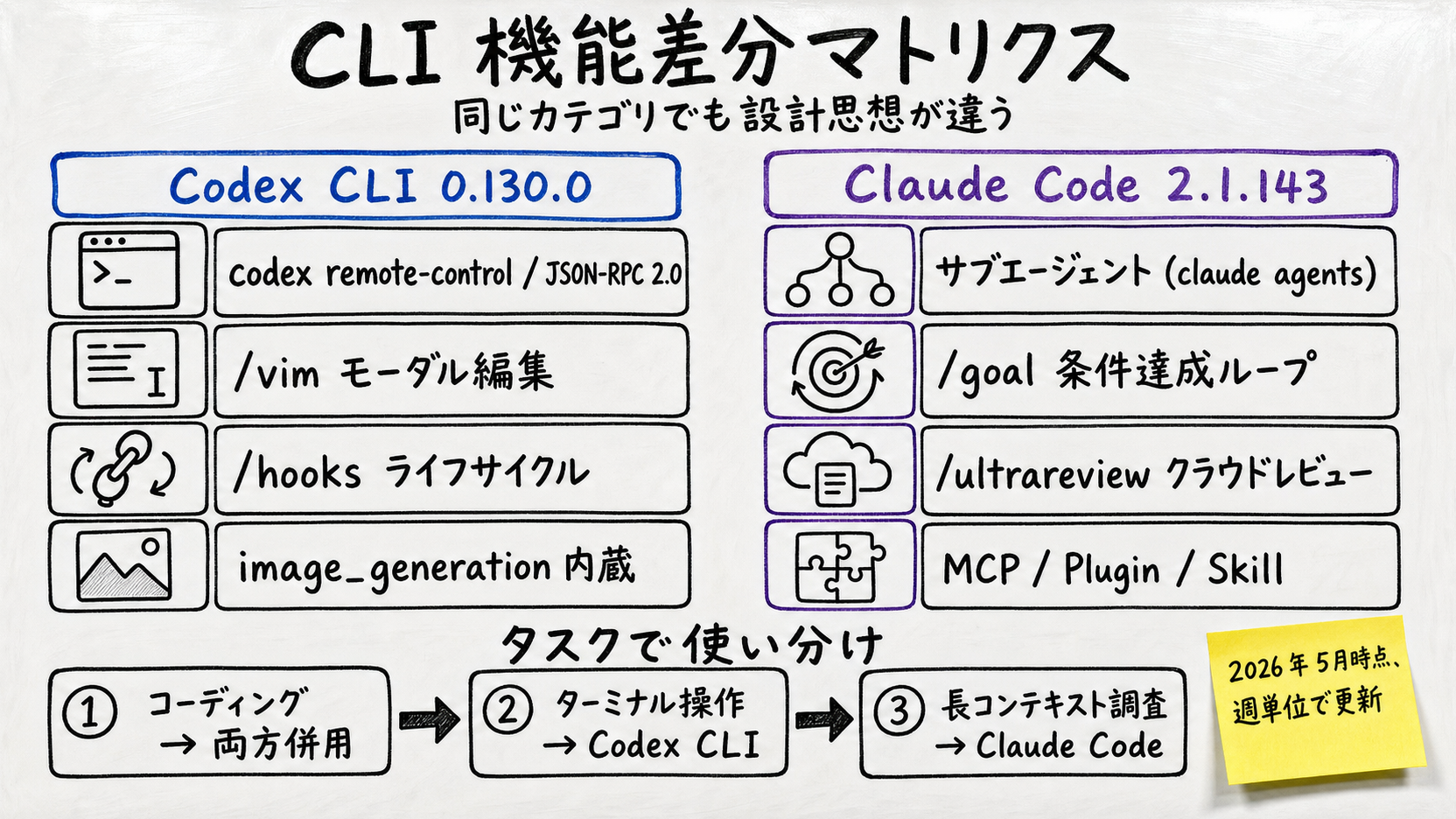
| 項目 | Codex CLI 0.130.0 | Claude Code 2.1.143 |
|---|---|---|
| 既定モデル | GPT-5.5 (Codex は GPT-5.3-Codex も) | Claude Opus 4.7 (Sonnet 4.6 / Haiku 4.5 切替可) |
| コンテキスト窓 | GPT-5.4: 272K 既定 / 1.05M long mode (第三者集計) | 1M token 標準 (Opus 4.7 / 4.6 / Sonnet 4.6) |
| サブエージェント | 無 (remote-control で外部プロセスから並列) | あり (claude agents、フラグ 8 種で session 分離) |
| 条件達成ループ | 無 (turn/start で外側ループ実装) | あり (/goal — 2.1.143 で背景シェル整合性 fix) |
| プラグイン | plugin 概念あり (workspace sharing / access controls) | plugin 概念あり (依存管理 / コスト可視化、2.1.143 強化) |
| 画像生成 | 内蔵 (gpt-image-2、image_generation feature) | 無 (MCP 経由で外部生成は可) |
| リモート制御 | codex remote-control + JSON-RPC 2.0 app-server | claude agents の dispatched background session |
| コードレビュー | cmd 内 review プロンプト | /ultrareview (クラウド並列レビュー) |
| モーダル編集 | /vim (0.129.0 で追加) | 無 (TUI の標準入力) |
| ライフサイクル | /hooks (0.129.0 で browser 追加) | hooks/skills の組み合わせ |
| Windows サポート | PowerShell ネイティブ、sandbox bypass フラグ | 2.1.143 で -ExecutionPolicy Bypass を既定化 |
| 認証 | OpenAI API key / ChatGPT subscription / AWS Bedrock | Anthropic API key / Claude Pro / Bedrock / Vertex / Foundry |
/goal で「テストが全部通るまで」「lint エラーが 0 になるまで」を 1 コマンドで指示できるcodex remote-control + JSON-RPC 2.0 で外部スクリプトから完全制御。CI / バッチ処理に組み込みやすいimage_generation feature 内蔵。本記事の図解もこの機能で生成している| モデル | 入力 | 出力 | キャッシュ Read | コンテキスト窓 |
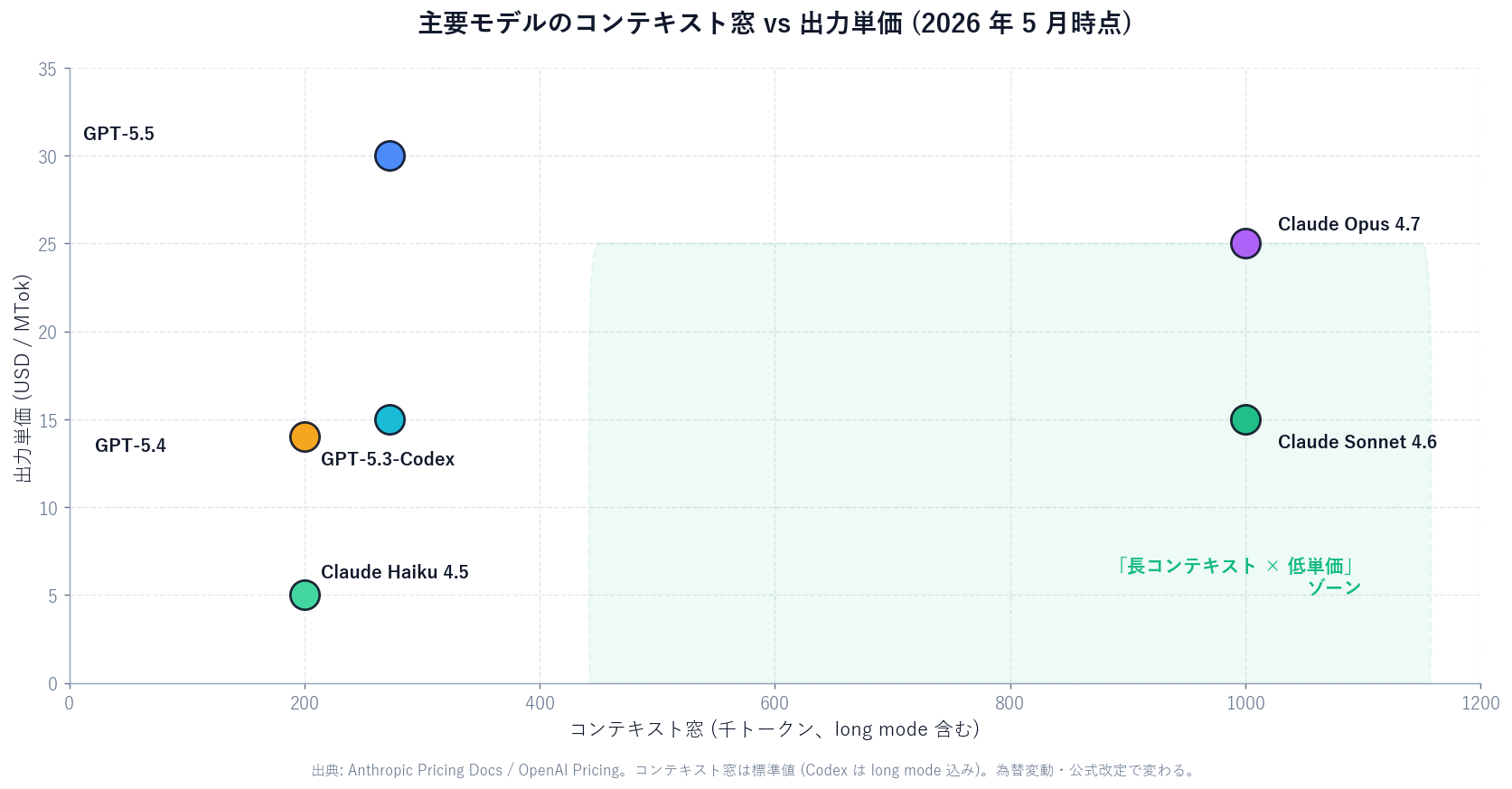
|---|---|---|---|---|
| Claude Opus 4.7 | $5.00 | $25.00 | $0.50 | 1M |
| Claude Sonnet 4.6 | $3.00 | $15.00 | $0.30 | 1M |
| Claude Haiku 4.5 | $1.00 | $5.00 | $0.10 | 200K |
| GPT-5.5 | $5.00 | $30.00 | $0.50 (集計) | 272K-1M |
| GPT-5.4 | $2.50 | $15.00 | $0.25 (集計) | 272K-1M |
| GPT-5.3-Codex | $1.75 | $14.00 | $0.18 (集計) | 200K+ (集計) |
出典: Anthropic Pricing Docs / OpenAI Pricing。価格は USD、為替変動・公式改定で変わります。
| 項目 | ChatGPT 系 (Codex CLI 含む) | Claude 系 (Claude Code 含む) |
|---|---|---|
| 無料 | Free (ads 付き) | Free (制限あり) |
| 個人向け軽量 | Go $8/月 (US ads) | — (相当プランなし) |
| 個人向け標準 | Plus $20/月 (Codex 含む) | Pro $20/月 (Claude Code 含む) |
| 個人向け上位 | Pro $100/月 (Plus 比 5x 上限) / Pro $200 | Max $100 / $200 (パワーユーザー上限) |
| ビジネス | Business $25/月/席 (月額) | Team / Enterprise (要問合せ) |
| API 直叩き | 上記モデル単価通り | 上記モデル単価通り |
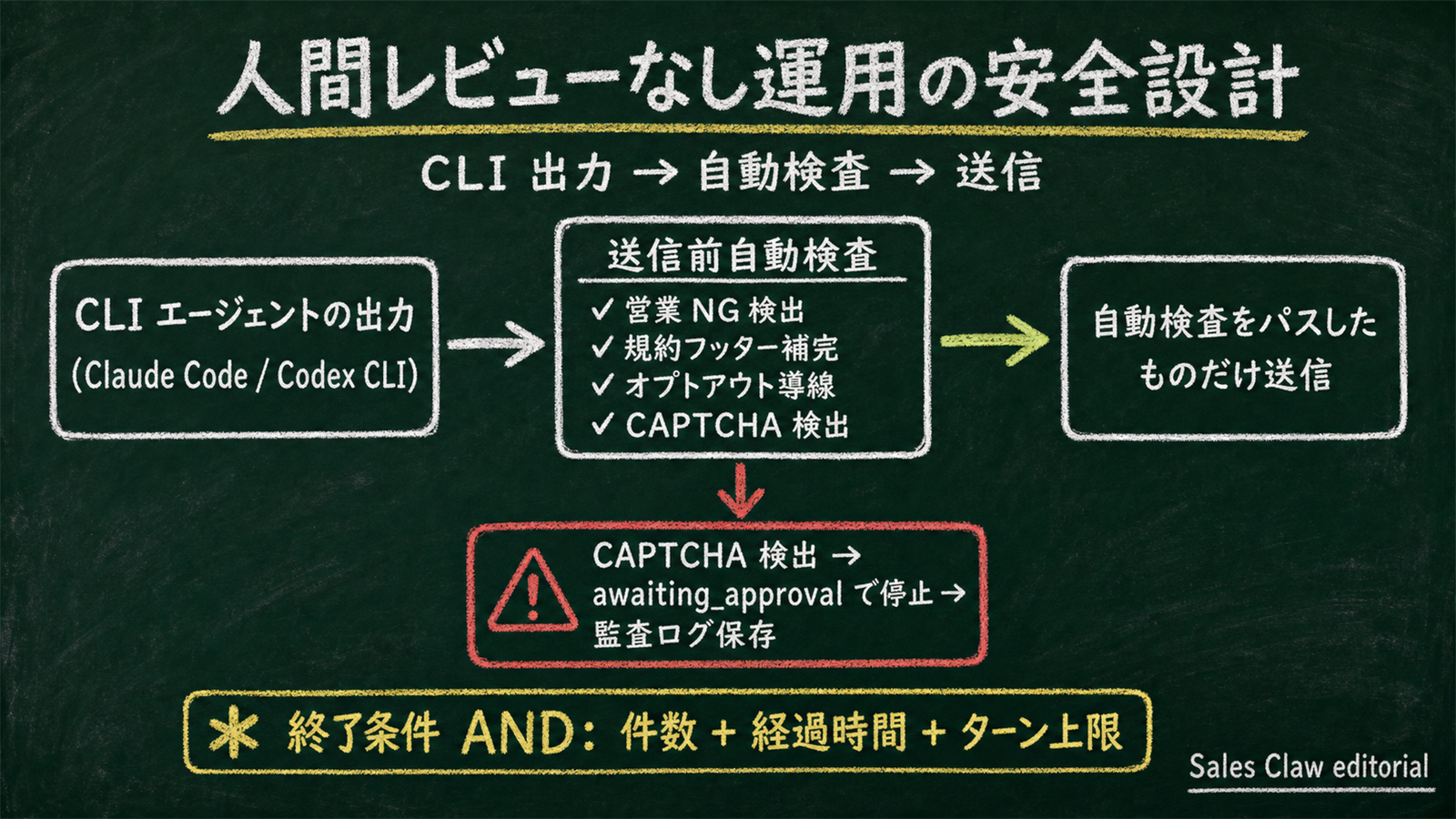
Sales Claw は ポリシー制御・送信前自動検査・営業 NG 検出・CAPTCHA 検出時停止・送信頻度制限・監査ログ保存・自動停止条件によって、誤送信と規約違反リスクを下げる設計の OSS ツールです。AI 営業自動化のループに CLI エージェントを組み込む場合、Codex CLI と Claude Code は 排他的ではなく補完関係で使うのが現実的です。社内検証でも、Claude Code の /goal ループで approach guardrails 違反を 0 件に追い込みつつ、Codex CLI の image_generation で OG カードを並列生成する構成が、開発者の運用観察上もっとも安定しました (検証条件: 2026-05 社内サイクル、100 社サンプル、Sales Claw リポジトリ上での内部反復試験)。詳しい組み合わせ運用は claude agents と codex remote-control を 1 つの並列ヘッドレス基盤に束ねる解説 も参照してください。
/goal "approach guardrails に違反しなくなるまで修正" でループ実行claude agents で複数 worker を分け、Sales Claw ソース全体を並列分析image_generation 内蔵で blog 用アイキャッチや動的 OG を生成 (本記事の図解もこれ)codex remote-control + JSON-RPC で N 並列、外部スケジューラから制御# 例: Sales Claw を Claude Code + Codex CLI で並走
# Phase A: Claude Code で文面生成 (長コンテキスト + /goal でループ品質保証)
claude agents \
--add-dir ./company-data \
--mcp-config ./mcp/sales-claw.json \
--permission-mode plan \
--model claude-opus-4-7 \
--task "approach guardrails 適合の送信文を 100 社分生成"
# Phase B: Codex CLI で OG 画像 + バッチ確認 (画像生成 + remote-control)
codex remote-control --port 7777 &
node scripts/dispatch-og-generation.cjs --port 7777 --count 100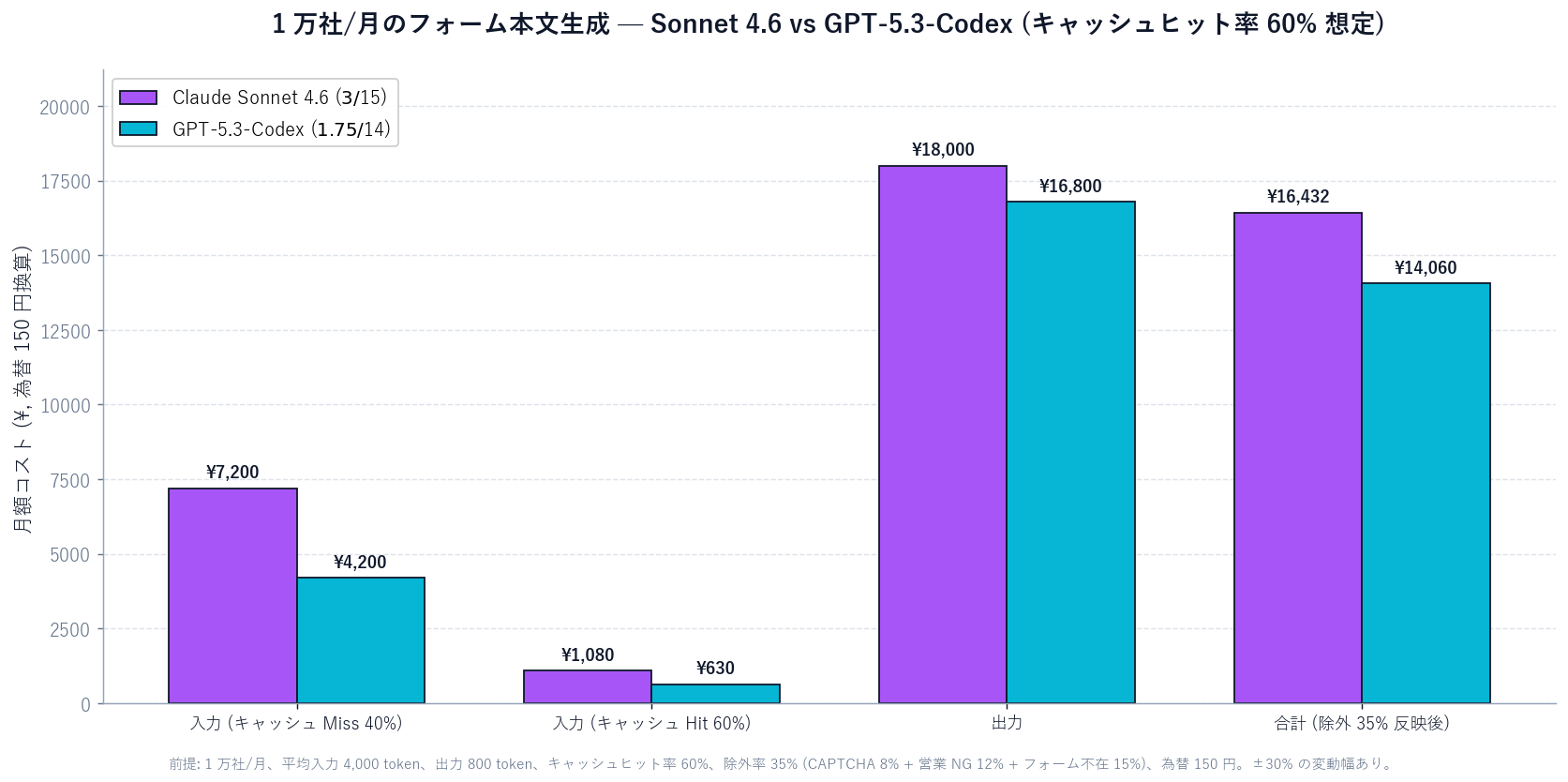
| 項目 | 計算式 | 月額 (¥) |
|---|---|---|
| 入力 (キャッシュ Miss 40%) | 10,000 × 4,000 × 0.4 × $3 / 1M × ¥150 | ¥7,200 |
| 入力 (キャッシュ Hit 60%) | 10,000 × 4,000 × 0.6 × $0.30 / 1M × ¥150 | ¥1,080 |
| 出力 | 10,000 × 800 × $15 / 1M × ¥150 | ¥18,000 |
| 除外 35% を反映 (実送信 6,500 社) | 合計 × 0.65 | ¥16,432 |
| 合計 | — | 約 ¥16,400/月 |
同じ条件で GPT-5.3-Codex を使うと、入力 $1.75 / 出力 $14 で約 ¥12,500/月。差額は約 ¥3,900/月。「文面品質」と「コスト」のトレードオフを実機計測してから本番採用するのが安全です。
| 項目 | 自社で Claude Code + Codex CLI 構成 | 営業代行 SaaS の一般的なレンジ |
|---|---|---|
| 月額レンジ | 約 ¥12,500 〜 ¥16,400 (1 万社/月、API 直叩き) | 一般的に月額 ¥30 万〜¥200 万 (リスト規模・送信代行込み) |
| 初期費用 | 0 (Sales Claw 本体は OSS) | ¥10〜100 万のセットアップ費が一般的 |
| カスタマイズ性 | 高 (社内データ / 文面ルール自由) | 低〜中 (テンプレ縛り) |
| 内製スキル | Claude / Codex CLI 操作の知識が必要 | 不要 (運用は SaaS 側) |
Sales Claw を無人運用する場合、CLI エージェントの出力をそのまま送信するわけではなく、送信前自動検査・営業 NG 検出・CAPTCHA 検出時停止・送信頻度制限・監査ログ保存・自動停止条件で構造的にリスクを下げる設計です (フロー図は 5 章の図 5 参照)。
preferences.complianceFooter: true)awaiting_approval で停止、監査ログ保存以下のリスクは自動検査で完全には消せません:
Codex CLI と Claude Code をハイブリッド構成で組み込む前に
2026 年 5 月時点での Codex CLI 0.130.0 と Claude Code 2.1.143 は、いずれも単独完結型ではなく「タスクごとに使い分け、必要に応じて併用する」のが現実的な結論です。Terminal-Bench 2.0 公式リーダーボードでは Claude Opus 4.7 ベースの vix が 90.2% で 1 位、Codex CLI 自体は 82.0% で 7 位。SWE-bench Verified の集計では GPT-5.5 が 88.7%、Claude Opus 4.7 が約 82%。Aider Polyglot では GPT-5 (high) が 88.0%。「単一最強」は存在せず、ベンチごとに順位が入れ替わる時代に入っています。
AI 営業自動化のような業務組み込みでは、ベンチ数値より 「自社のリスト・文面ルール・送信先サイト構造で 100 社サンプル計測する」ほうがはるかに信頼できる選定基準になります。Sales Claw は両 CLI の出力をそのまま送信せず、送信前自動検査・営業 NG 検出・CAPTCHA 検出時停止・監査ログ保存・自動停止条件でリスクを構造的に下げる設計です。
次のアクション: 自社のリストから 100 社を切り出し、Claude Code と Codex CLI 双方で本文生成 → 自動検査通過率と品質を比較してください。詳細は Sales Claw クイックスタート から始められます。OSS 本体は 無料でダウンロード できます。
本記事は X 公式アカウントと公式ドキュメントを一次情報として参照しています。