業界トレンド
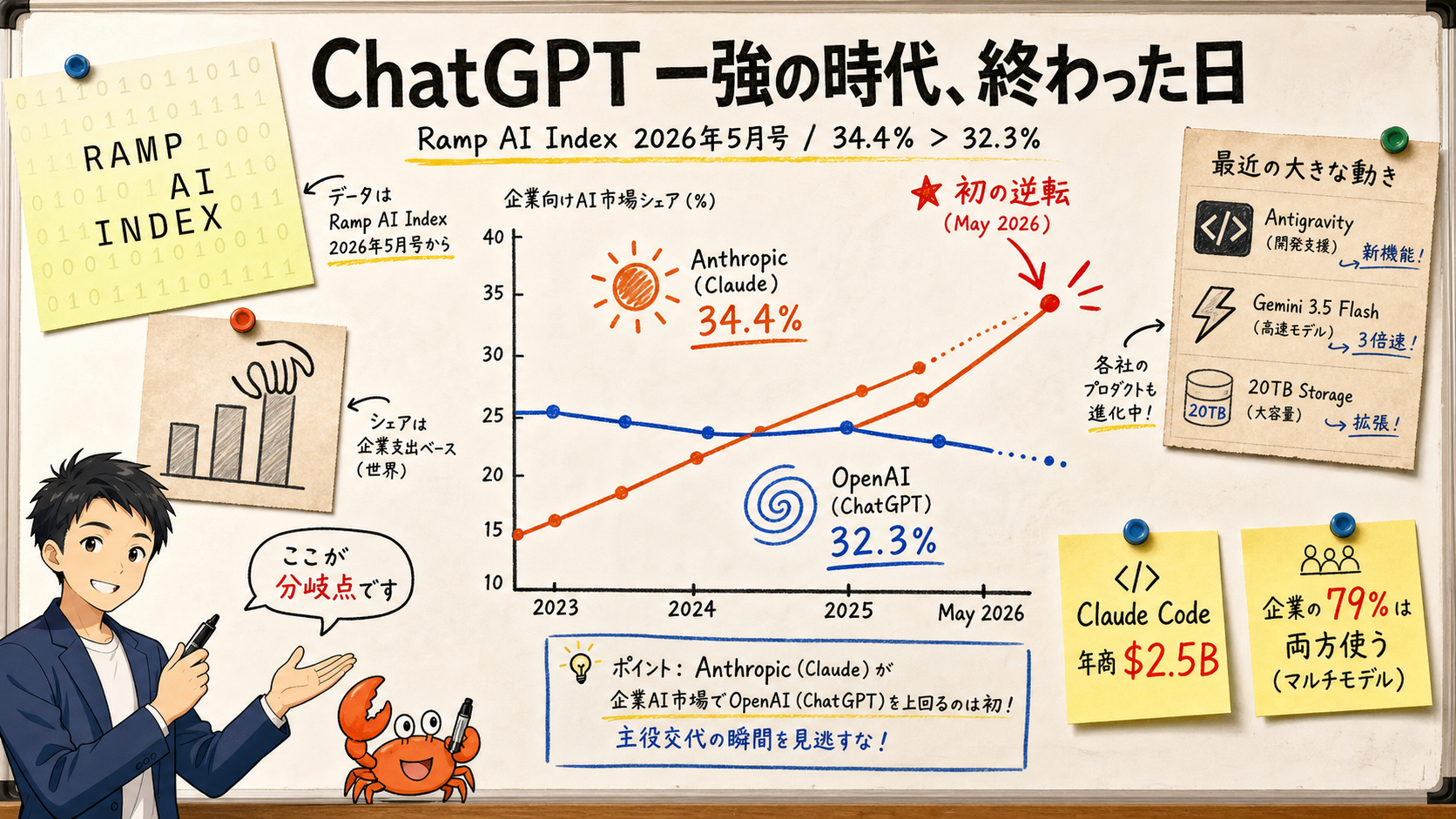
Anthropic Overtakes OpenAI for the First Time — The May 2026 "Changing of the Guard" in Enterprise AI, Explained for Non-Experts
14 分
Codex CLI 0.130.0 and Claude Code 2.1.143 reshuffle rankings depending on the benchmark axis. We walk through Terminal-Bench 2.0 / SWE-bench Verified / Aider Polyglot (official + third-party aggregates), API pricing, CLI feature deltas, and AI sales-automation fit — all from the Sales Claw maintainer's seat.

中澤 圭志
@keishi_nakazawaSales Claw maintainer

Key Facts
Latest
Codex CLI 0.130.0 (2026-05-08) / Claude Code 2.1.143 (2026-05-15)
Default model
GPT-5.5 (2026-04-23) / Claude Opus 4.7 (2026-04-16)
Terminal-Bench 2.0
vix + Opus 4.7 90.2% (#1) / Codex CLI + GPT-5.5 82.0% (#7)
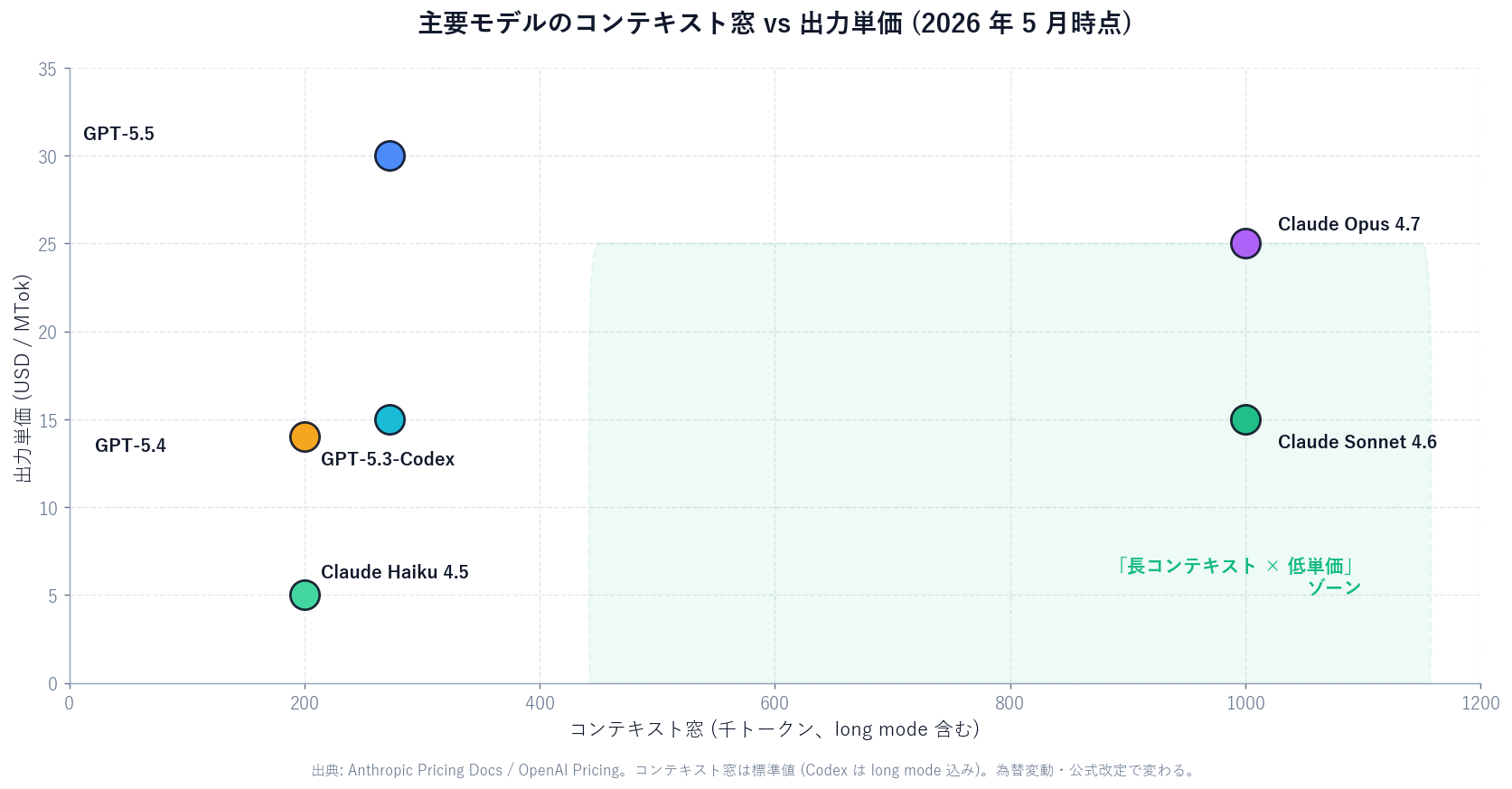
API pricing (in/out)
Opus 4.7 $5/$25 / GPT-5.5 $5/$30 / GPT-5.3-Codex $1.75/$14 per MTok
"Which is stronger — Codex CLI or Claude Code? I want a cross-cut comparison on 2026-May official benchmarks, with cost and task fit included, so I can pick the right one in the field." — We answer this using the Terminal-Bench 2.0 official leaderboard, Aider Polyglot, SWE-bench Verified aggregates, plus Anthropic / OpenAI official docs and GitHub releases — through the lens of embedding these agents in AI sales automation.
As of May 2026, the latest versions are Codex CLI 0.130.0 (released 2026-05-08) and Claude Code 2.1.143 (released 2026-05-15). Their backing flagship models are GPT-5.5 (rolled out 2026-04-23) and Claude Opus 4.7 (released 2026-04-16). Benchmark rankings flip depending on which axis you measure, so rather than a simple winner, read these as "task-by-task fit".
Sources: OpenAI Codex official changelog / Claude Code official changelog / Anthropic Newsroom / Terminal-Bench official leaderboard (tbench.ai) / Aider official docs / Claude / OpenAI official pricing pages. We only cite official information at publish time; third-party aggregates are explicitly labeled.
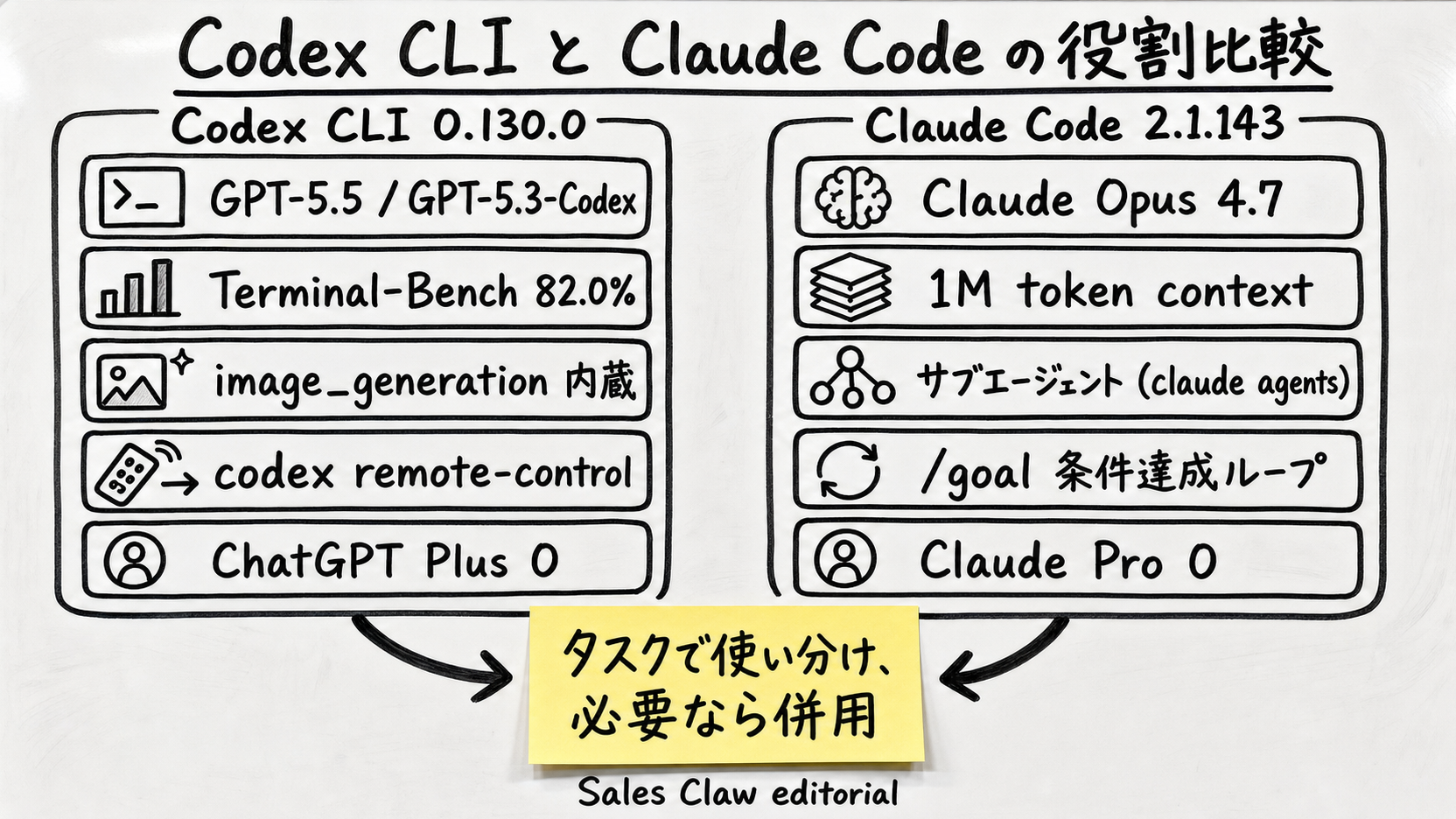
codex remote-control for full headless control from external processes; built-in image generation (gpt-image-2).@openai/codex on npm, launched via codex.xhigh effort level and Fast mode.claude agents), /goal for completion-condition loops, /ultrareview, Plugin / Skill / MCP. 1M-token context standard.@anthropic-ai/claude-code on npm, launched via claude.tbench.ai's official leaderboard shows the top 10 as of 2026-05-15:
| Rank | Agent | Model | Score | Date |
|---|---|---|---|---|
| 1 | vix | Claude Opus 4.7 | 90.2% ± 2.1 | 2026-05-15 |
| 2 | JJAgent | Multiple | 87.1% | 2026-05-15 |
| 3 | NexAU-AHE | GPT-5.5 | 84.7% | 2026-05-14 |
| 7 | Codex CLI | GPT-5.5 | 82.0% | 2026-04-23 |
| 9 | WOZCODE | Claude Opus 4.7 | 80.2% | 2026-05-14 |
SWE-bench Verified is the heavyweight benchmark using real GitHub issues. OpenAI paused self-reporting in Feb 2026 over contamination concerns, so current numbers come from third-party trackers like Epoch AI.

Anthropic explicitly states in the Opus 4.7 announcement that "excluding any problems that show signs of memorization, Opus 4.7's margin of improvement over Opus 4.6 holds", signaling transparency on contamination. We treat these numbers as "baselines with ±several percent error".
Aider's official leaderboard evaluates against 225 Exercism problems across C++ / Go / Java / JavaScript / Python / Rust.
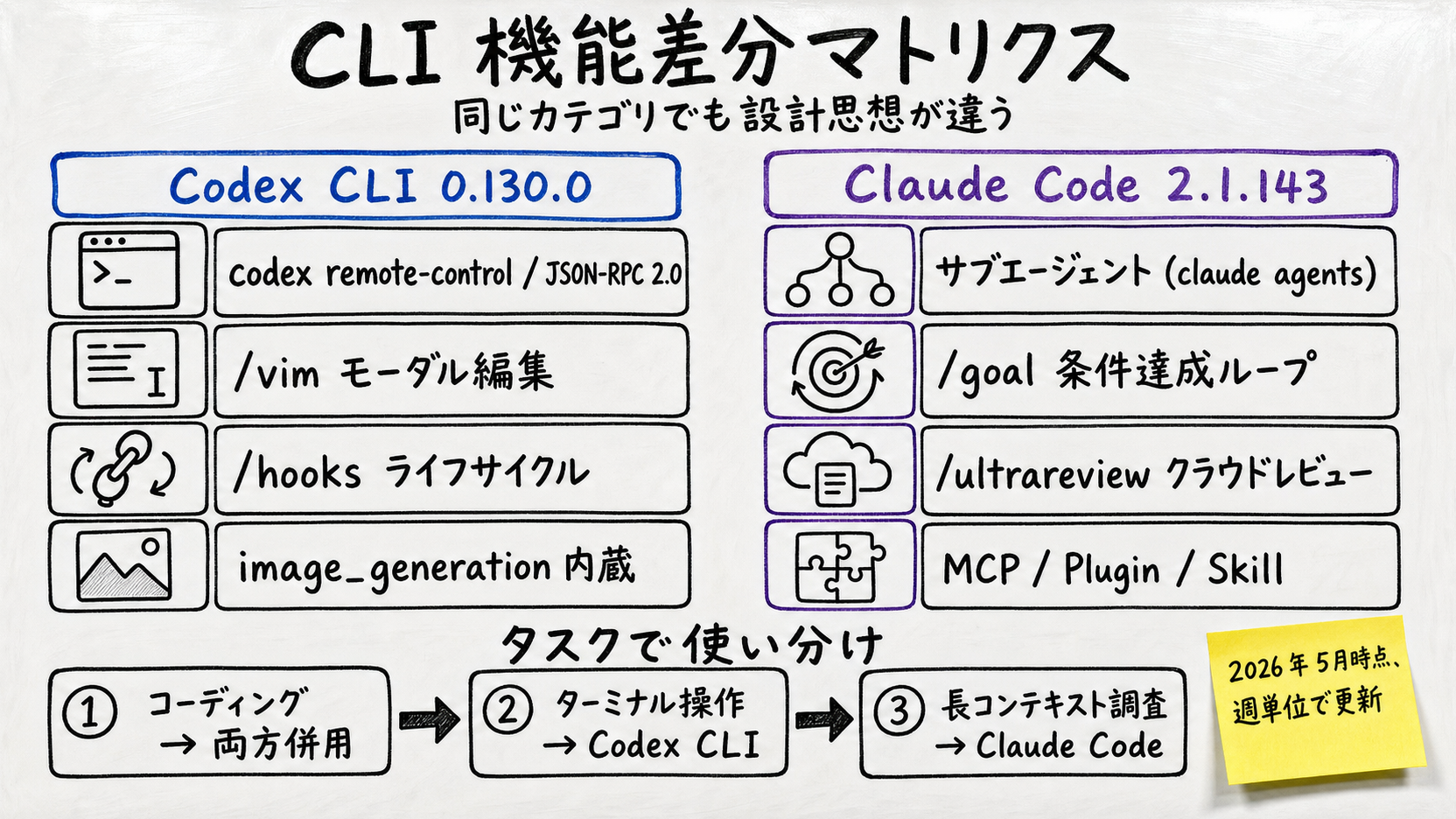
| 項目 | Codex CLI 0.130.0 | Claude Code 2.1.143 |
|---|---|---|
| Default model | GPT-5.5 (Codex also offers GPT-5.3-Codex) | Claude Opus 4.7 (Sonnet 4.6 / Haiku 4.5 switchable) |
| Context window | GPT-5.4: 272K default / 1.05M long mode (third-party) | 1M tokens standard (Opus 4.7 / 4.6 / Sonnet 4.6) |
| Subagents | No (parallelism via remote-control from external processes) | Yes (claude agents — 8 flags for session isolation) |
| Completion-condition loop | No (implement outer loop via turn/start) | Yes (/goal — 2.1.143 fixes background-shell consistency) |
| Plugins | Yes (workspace sharing / access controls) | Yes (dependency management / cost visibility, 2.1.143) |
| Image generation | Built-in (gpt-image-2 via image_generation feature) | No (external generation possible via MCP) |
| Remote control | codex remote-control + JSON-RPC 2.0 app-server | claude agents dispatched background sessions |
| Code review | In-cmd review prompts | /ultrareview (cloud parallel review) |
| Modal editing | /vim (added in 0.129.0) | No (standard TUI input) |
| Lifecycle | /hooks (browser added in 0.129.0) | hooks / skills combination |
| Windows support | Native PowerShell, sandbox bypass flag | 2.1.143 defaults to -ExecutionPolicy Bypass |
| Auth | OpenAI API key / ChatGPT subscription / AWS Bedrock | Anthropic API key / Claude Pro / Bedrock / Vertex / Foundry |
/goal drives "until all tests pass" or "until lint = 0" in one command.codex remote-control + JSON-RPC 2.0 enables full control from external scripts — perfect for CI / batch.image_generation built in. The figures in this article are generated with it.| Model | Input | Output | Cache Read | Context |
|---|---|---|---|---|
| Claude Opus 4.7 | $5.00 | $25.00 | $0.50 | 1M |
| Claude Sonnet 4.6 | $3.00 | $15.00 | $0.30 | 1M |
| Claude Haiku 4.5 | $1.00 | $5.00 | $0.10 | 200K |
| GPT-5.5 | $5.00 | $30.00 | $0.50 (agg.) | 272K-1M |
| GPT-5.4 | $2.50 | $15.00 | $0.25 (agg.) | 272K-1M |
| GPT-5.3-Codex | $1.75 | $14.00 | $0.18 (agg.) | 200K+ (agg.) |
Sources: Anthropic Pricing Docs / OpenAI Pricing. Prices in USD; subject to FX moves and official revisions.
| 項目 | ChatGPT family (Codex CLI included) | Claude family (Claude Code included) |
|---|---|---|
| Free | Free (ads) | Free (limits apply) |
| Individual light | Go $8/mo (US, ads) | — (no direct equivalent) |
| Individual standard | Plus $20/mo (includes Codex) | Pro $20/mo (includes Claude Code) |
| Individual upper | Pro $100/mo (5x Plus limits) / Pro $200 | Max $100 / $200 (power-user ceilings) |
| Business | Business $25/seat (monthly) | Team / Enterprise (contact sales) |
| Direct API | Per-token rates above | Per-token rates above |
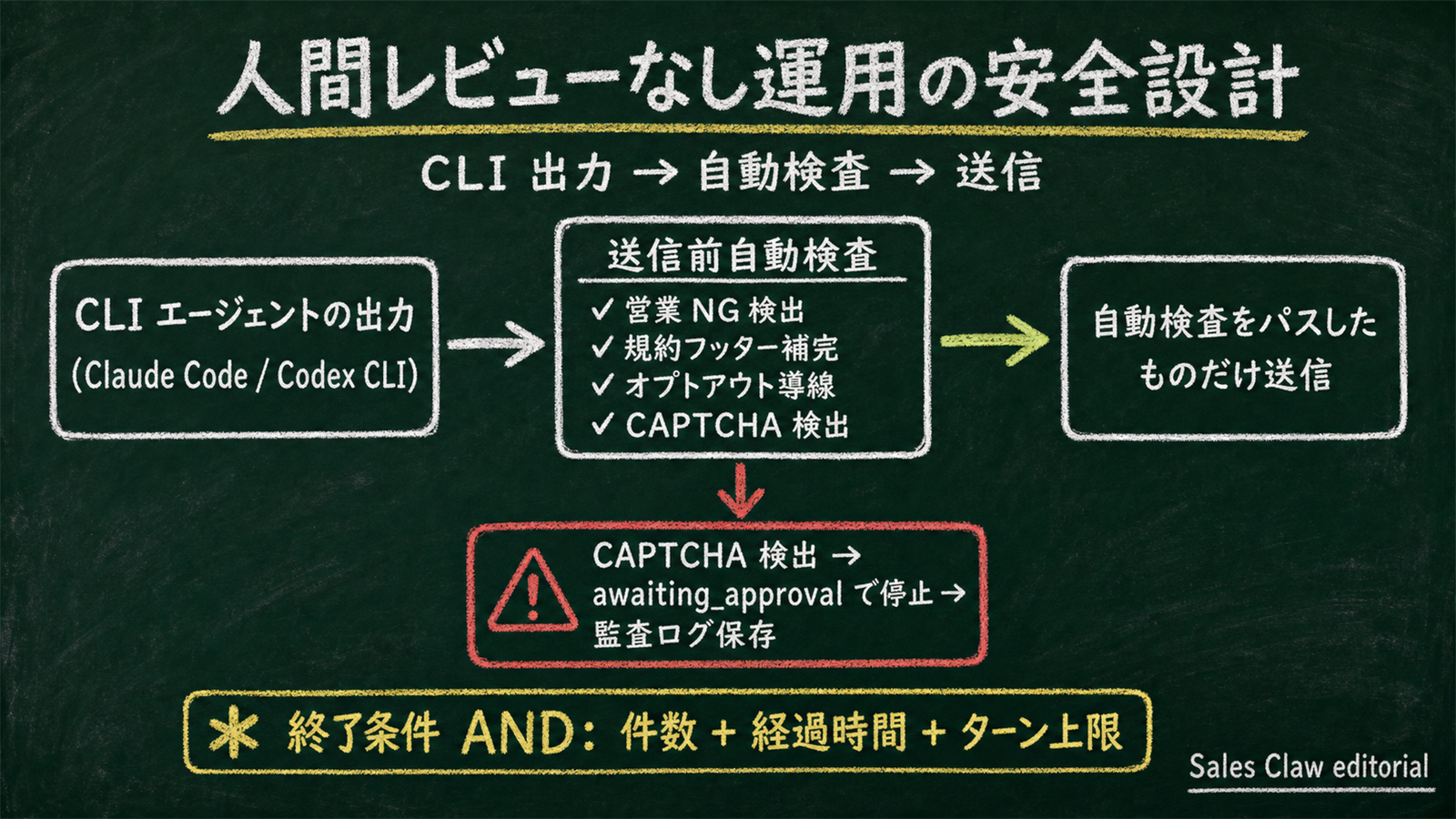
Sales Claw is an OSS tool designed to reduce mis-send and TOS-violation risk through policy control, pre-send automated checks, sales-NG detection, halting on CAPTCHA detection, send-frequency limits, audit log preservation, and auto-stop conditions. When embedding CLI agents into the loop, Codex CLI and Claude Code are complementary, not exclusive. In our own internal verification (May 2026, 100-company sample on the Sales Claw repo), the most stable setup paired Claude Code's /goal loop driving approach guardrails violations to zero with Codex CLI's image_generation producing OG cards in parallel. See our walkthrough on bundling claude agents and codex remote-control into one parallel headless platform for details.
/goal "loop until no approach-guardrail violations"claude agents parallelizes workers across Sales Claw source.image_generation for blog covers and dynamic OG (the figures in this article come from it).codex remote-control + JSON-RPC for N-way parallel from an external scheduler.# Run Sales Claw with Claude Code + Codex CLI side by side
# Phase A: Claude Code generates copy (long context + /goal loop)
claude agents \
--add-dir ./company-data \
--mcp-config ./mcp/sales-claw.json \
--permission-mode plan \
--model claude-opus-4-7 \
--task "Generate guardrail-compliant copy for 100 companies"
# Phase B: Codex CLI handles OG image + batch verification
codex remote-control --port 7777 &
node scripts/dispatch-og-generation.cjs --port 7777 --count 100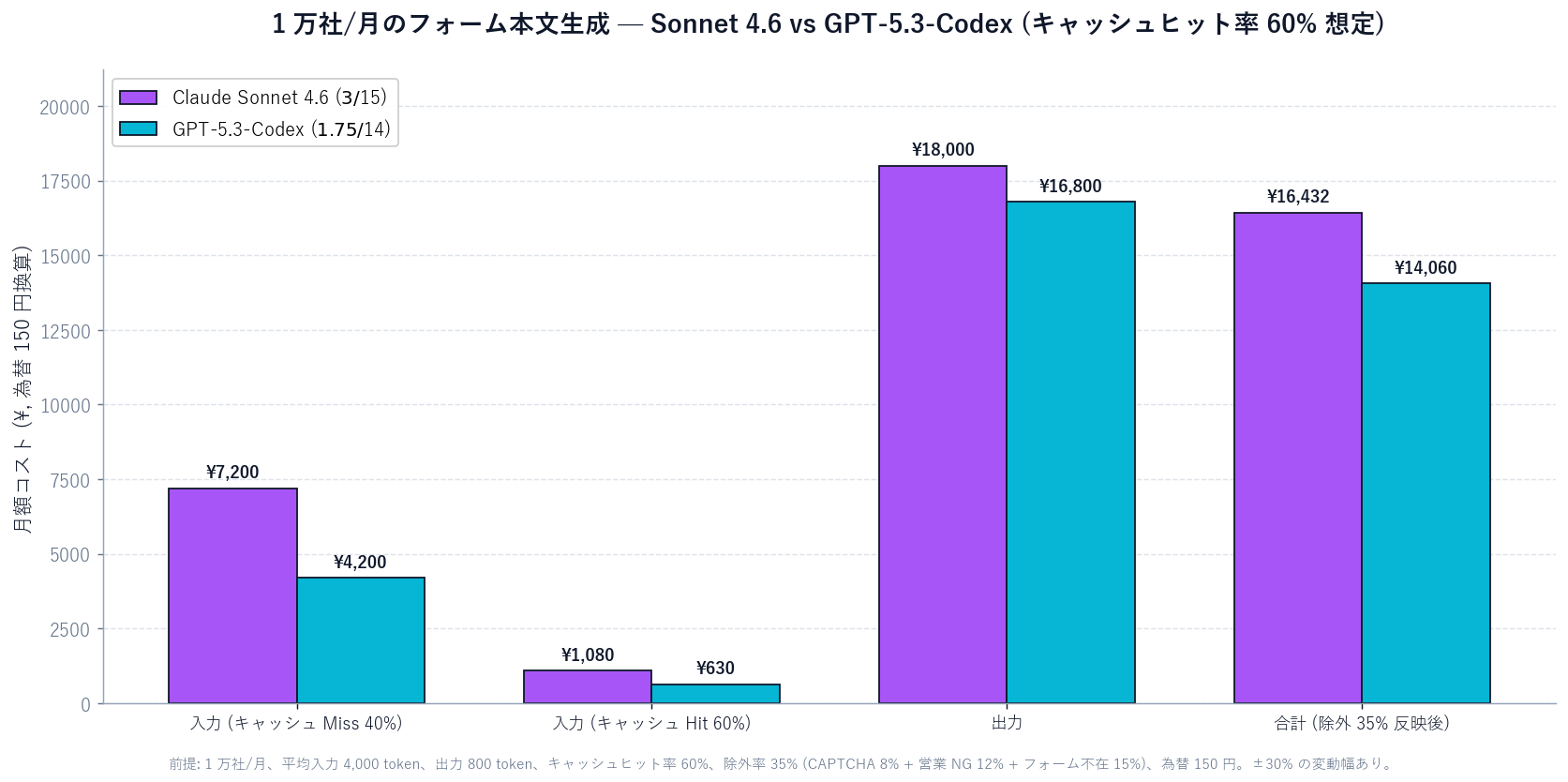
Under identical conditions, GPT-5.3-Codex (input $1.75 / output $14) comes to about ¥12,500 / month. Delta vs Sonnet 4.6 is ~¥3,900 / month. Measure on real data before adopting — the quality vs cost tradeoff is workload-specific.
| 項目 | In-house Claude Code + Codex CLI | Typical sales-agency SaaS |
|---|---|---|
| Monthly range | Approx. ¥12,500–¥16,400 (10K companies, direct API) | Generally ¥300K–¥2M (list scale, send-execution included) |
| Setup cost | 0 (Sales Claw is OSS) | ¥100K–¥1M typical |
| Customization | High (own data / copy rules) | Low–medium (template-bound) |
| In-house skill required | Claude / Codex CLI operation | Not required (SaaS-operated) |
Sales Claw doesn't ship CLI agent output directly — it applies pre-send automated checks, sales-NG detection, halting on CAPTCHA detection, send-frequency limits, audit log preservation, and auto-stop conditions to reduce risk structurally (see Figure 5 in section 5 for the full flow).
preferences.complianceFooter: true)awaiting_approval, audit loggedBefore going hybrid with Codex CLI + Claude Code
As of May 2026, Codex CLI 0.130.0 and Claude Code 2.1.143 are best read as "pick by task; combine where it fits" rather than "one CLI to rule them all". Terminal-Bench 2.0 puts Claude-Opus-4.7-based vix at 90.2% (rank 1) and Codex CLI itself at 82.0% (rank 7); SWE-bench Verified aggregates put GPT-5.5 at 88.7% and Claude Opus 4.7 around 82%; Aider Polyglot puts GPT-5 (high) at 88.0%. There is no single winner — rankings reshuffle per benchmark.
For embedded-product use like AI sales automation, "measure 100 companies of your own list / copy rules / target sites" is a far more trustworthy selection signal than benchmark ranks. Sales Claw doesn't ship CLI output as-is — it reduces risk structurally with pre-send checks, sales-NG detection, CAPTCHA halts, audit log, and auto-stop conditions.
Next step: slice 100 companies from your list, run both Claude Code and Codex CLI for body generation, then compare pre-send-check pass rates and quality side by side. Start at the Sales Claw quick start. The OSS source is also free to download.
This is a convenience English translation of the Japanese-language original. In case of any discrepancy, the Japanese version is authoritative.
本記事は X 公式アカウントと公式ドキュメントを一次情報として参照しています。
この記事の著者
中澤 圭志
Sales Claw maintainer
Designs and develops Sales Claw. Writes from the field on B2B sales automation and applied AI.