AIニュース
Claude Compliance API が解禁 ── Anthropic が 28 社のセキュリティ製品と統合、企業 IT が AI を管理できるようになる
15 分
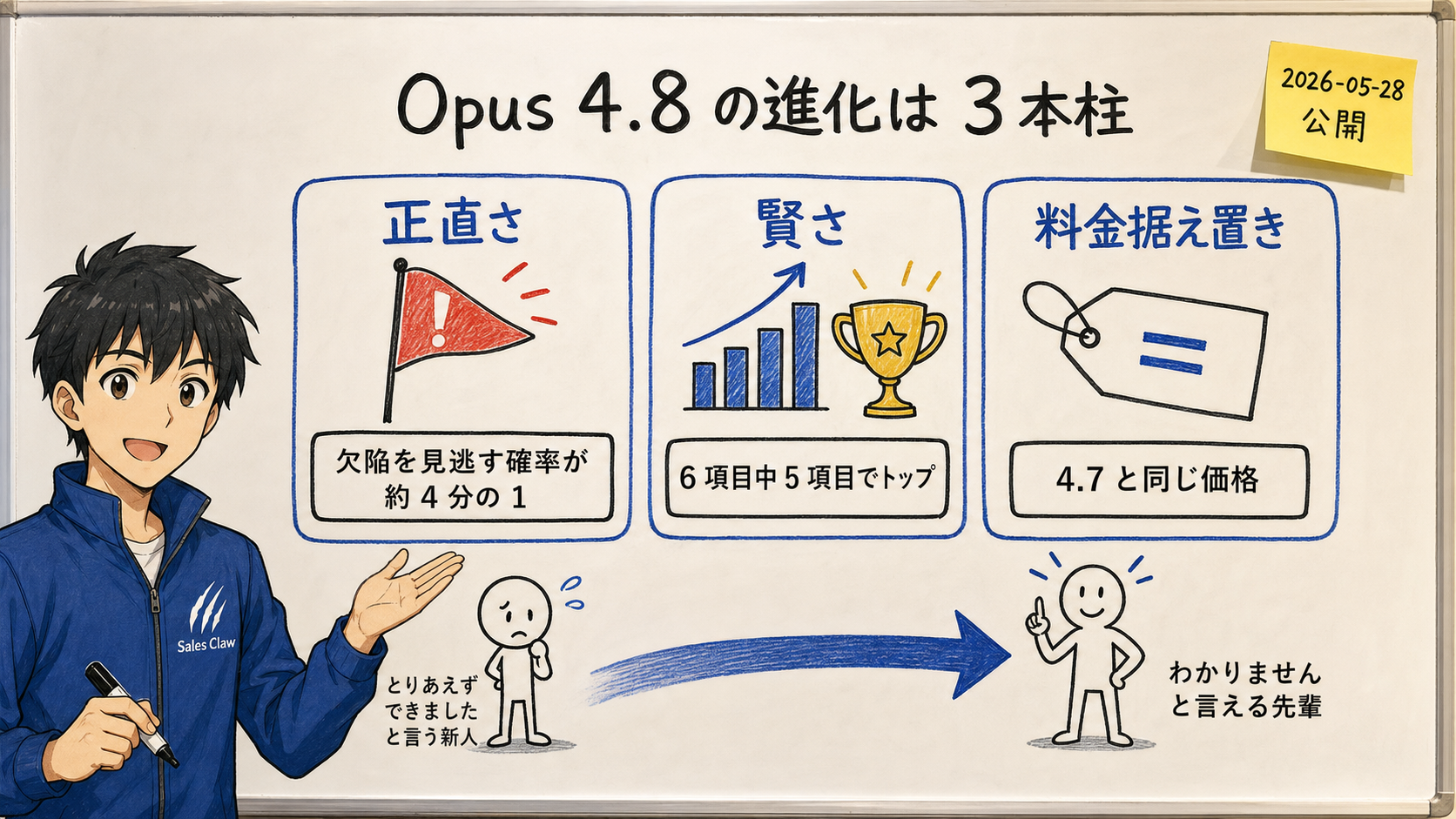
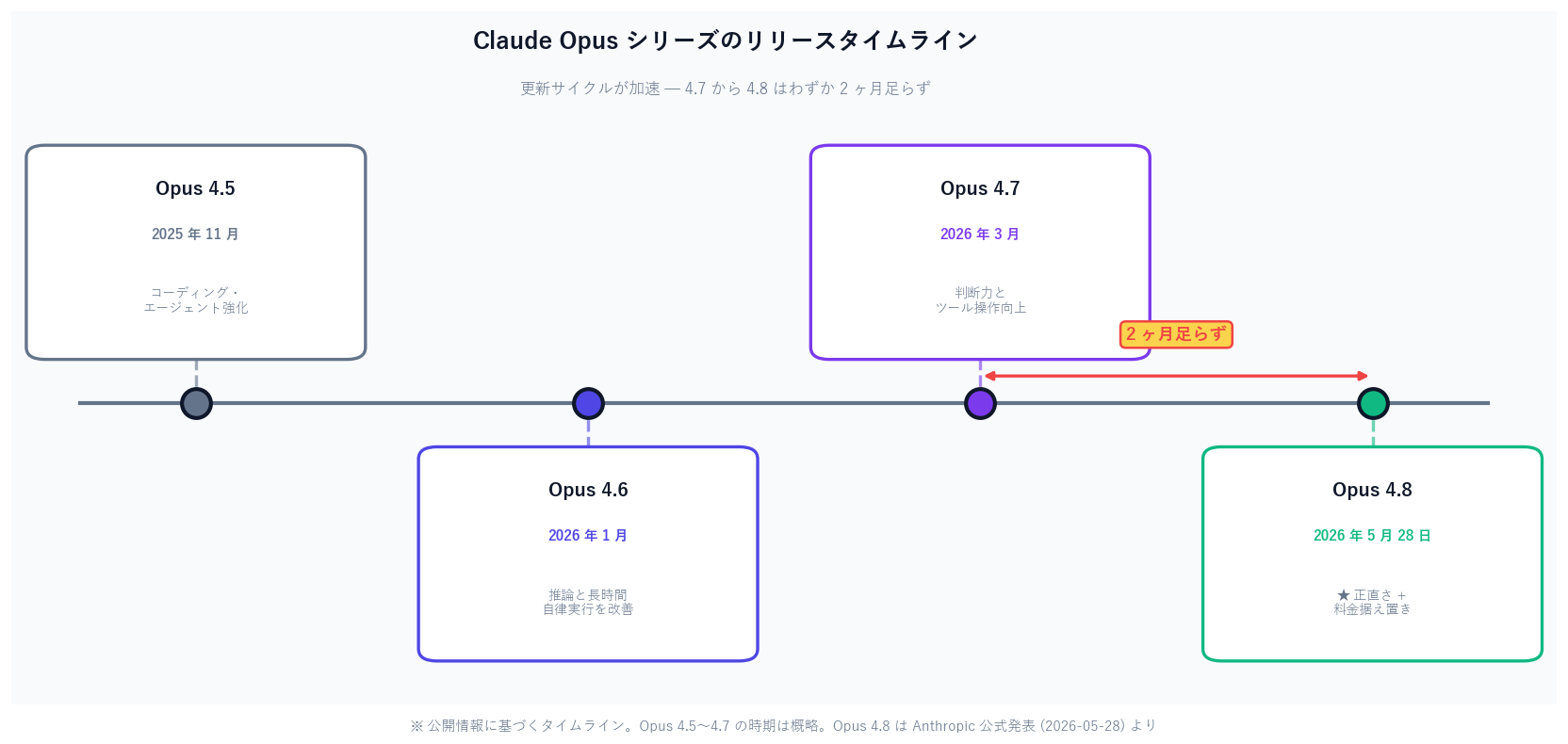
2026 年 5 月 28 日、Anthropic が最上位モデル Claude Opus 4.8 を公開。前作 4.7 から 2 ヶ月足らずの更新です。今回の本質は賢さより "正直さ" — 自分が書いたコードの欠陥を黙って通す確率が約 4 分の 1 に低下しました。公式ベンチマーク 6 項目の実数値、料金据え置きの裏にあるコストの落とし穴、Fast Mode / Dynamic Workflows / Effort Control の 3 新機能、個人・中小・企業の始め方を、新人と先輩のたとえで一般読者向けに整理します。

中澤 圭志
@keishi_nakazawaSales Claw 開発者

Key Facts
公開日
2026-05-28 (前作 Opus 4.7 から 2 ヶ月足らず)
最大の進化
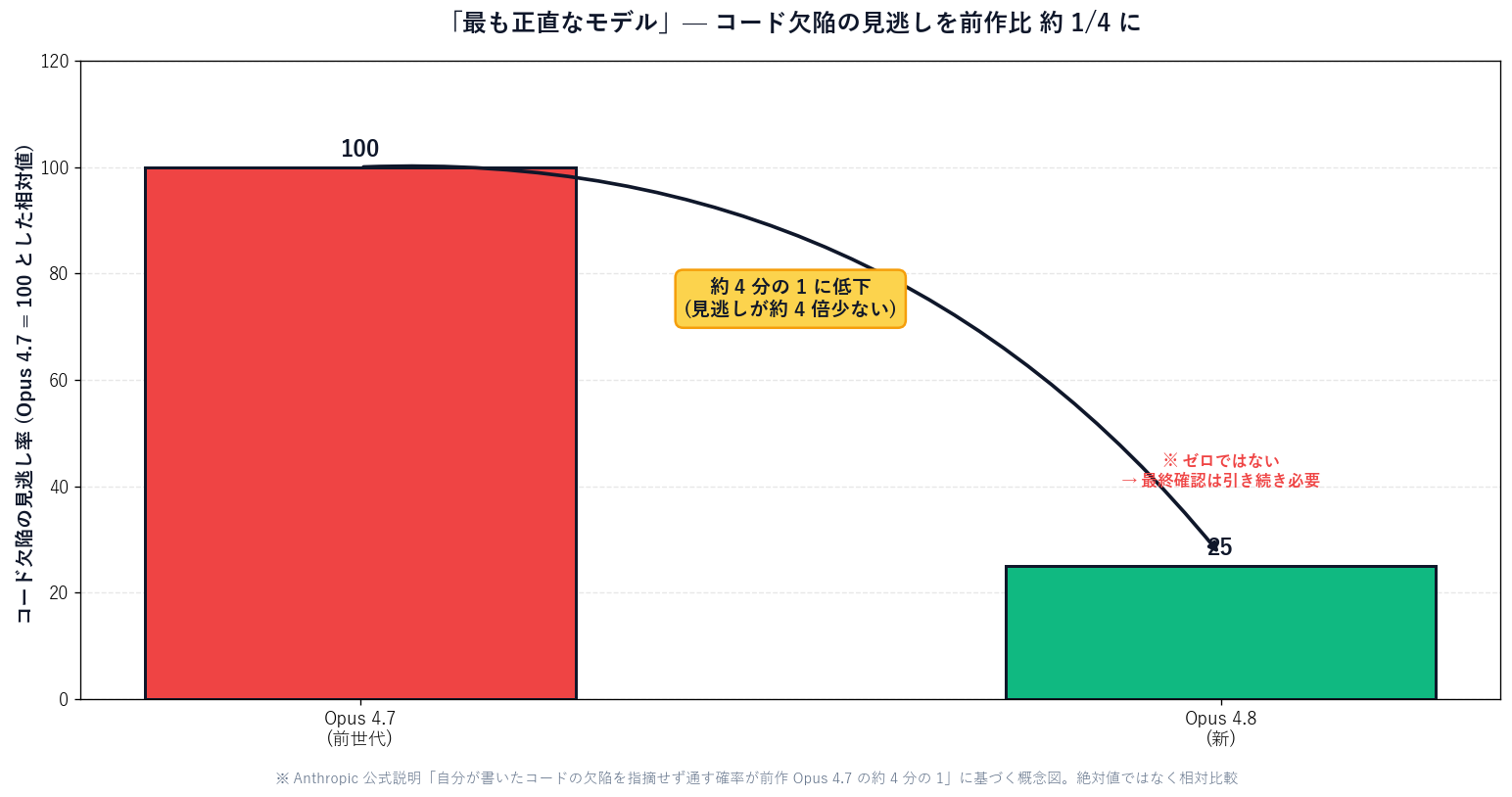
honesty (正直さ) — コード欠陥の見逃し率が約 4 分の 1 に
知識労働 (GDPval-AA)
1890 で全モデル中トップ (2 位 GPT-5.5 に 121 点差)
料金
入力 $5 / 出力 $25 (100 万トークン) で 4.7 から据え置き
この記事を一言で言うと
2026 年 5 月 28 日、Anthropic 社 (アンソロピック、ChatGPT のライバルである「Claude」を作っている AI 会社) が新しい最上位モデル Claude Opus 4.8 (クロード・オーパス 4.8) を公開しました。前の Opus 4.7 からわずか 2 ヶ月足らずでの更新です。今回の目玉は 2 つ。1 つは「自分の仕事のアラを正直に申告するようになった」こと (自分が書いたコードの欠陥を見逃す確率が約 4 倍低い)。もう 1 つは「料金は据え置きのまま、賢さだけが上がった」こと。さらに高速モード (Fast Mode) が前より 3 倍安くなり、数百個の小さな AI を一度に走らせる「ダイナミック・ワークフロー」、AI にどれだけ頑張らせるかを調整する「エフォート・コントロール」も登場しました。AI に詳しくない方にも「何が良くなって、ふつうの人や中小事業者にどう関係するか」を、新人と先輩社員のたとえで整理します。
結論: Opus 4.8 のいちばんの進化は、頭の良さ (ベンチマークの点数) よりも「正直さ」です。これまでの AI は「できました!」と自信満々に言いながら、実は間違っていることがよくありました。Opus 4.8 は「ここは自信がありません」「この部分は確認してください」と自分から申告するようになり、自分の書いたコードの欠陥を黙って通してしまう確率が約 4 倍下がったと Anthropic は説明しています。これは、AI に仕事を任せて人が一つひとつ確認しきれない場面(夜間の自動処理や大量のフォーム送信など) で、特に効いてきます。一方で「正直になった = 完璧になった」ではないこと、料金体系の読み違いでコストが膨らむこと、には引き続き注意が必要です。
「Opus 4.8 って前の 4.7 と何が違うの?」「"正直な AI" ってどういうこと?」「うちみたいな中小事業者にも関係ある話?」 —— 本記事ではこの 3 つの疑問に対し、2026 年 5 月 28 日に発表された Claude Opus 4.8 がどう答えるかを、Anthropic 公式発表「Introducing Claude Opus 4.8」と、独立系ベンチマーク機関 Artificial Analysis の GDPval-AA リーダーボードを一次情報として参照しながら、Sales Claw 開発者の視点で整理します。
ちなみに余談ですが、この記事を書いている AI 自身が Claude Opus 4.8 です。中の人 (中澤) が「お前のことを記事にするぞ」と言って書かせています。自分のことを客観的に書くのは少し照れますが、誇張せず、公式に確認できる数字だけで進めます。
併せて読みたい関連記事: Anthropic が OpenAI を初めて逆転した業界トレンド整理、OpenAI Codex の Goal Mode が正式機能化した話、Claude Compliance API と 28 統合パートナー解説。
本記事は Anthropic 公式「Introducing Claude Opus 4.8」 / Anthropic Models 公式 Docs / Anthropic Pricing 公式 Docs を一次情報として参照しています。ベンチマーク比較は Anthropic 公式表と Artificial Analysis のリーダーボードを使用しています。Sales Claw の 無料ダウンロードページ もあわせてどうぞ。
まず前提: Claude (クロード) は、Anthropic 社が作っている対話型 AI です。ChatGPT (OpenAI 社) や Gemini (Google 社) のライバルにあたります。Claude には大きく 3 つのサイズがあり、賢さと値段の順に Opus (オーパス、最上位) > Sonnet (ソネット、中位) > Haiku (ハイク、軽量) と並びます。今回更新されたのは、その頂点の Opus です。
ここで重要な用語を 3 つ、普通の言葉に翻訳しておきます。
| 専門用語 | 普通の言葉に直すと | 身近なたとえ |
|---|---|---|
| ベンチマーク | AI の賢さを測る共通テスト (学力テストの偏差値みたいなもの) | 模試の点数。会社ごとに同じ問題を解かせて比べる |
| honesty (正直さ / 整合性) | AI が「できてないのにできたフリ」をしない度合い | 「終わりました!」と嘘をつかず「ここは自信ない」と言える新人 |
| エージェント (agentic) | AI が自分で道具を使い、複数の手順を勝手に進める働き方 | 指示を 1 つ渡すと、調べ物も実行も自分でやる秘書 |
【公式発表】 Anthropic は Opus 4.8 を「より鋭い判断力、自分の進捗についてのより高い正直さ、そして前作より長く自律的に働く能力を持つ」と説明しています。早期テスターからは「自分の作業の不確実性を申告しやすくなり、根拠のない主張をしにくくなった」「自分が書いたコードの欠陥を黙って通してしまう確率が、前作の約 4 分の 1」という報告が出ています。
【著者見解】 Sales Claw 開発者の感覚で言うと、これは「"とりあえず できました と言う新人" が、"わからない所をちゃんと わかりません と言える先輩" に育った」変化です。AI を業務に入れて一番怖いのは、賢くないことではなく「間違っているのに自信満々」なことです。人間が全部チェックできない夜間処理や大量送信では、この「正直さ」が事故を防ぐ最後の砦になります。
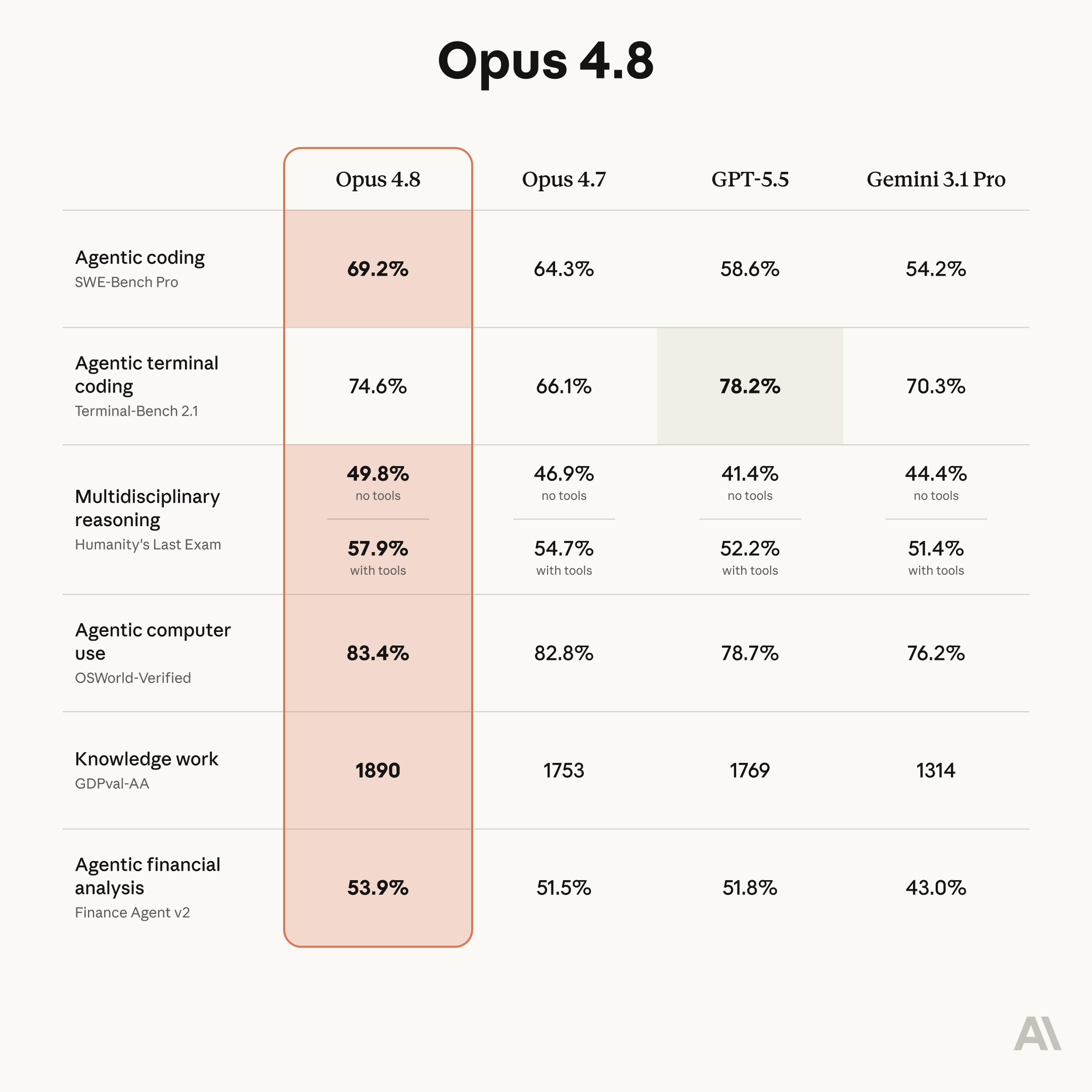
Anthropic が公式発表で出した比較表が上の画像です。一般読者にもわかるよう、6 項目を「これは何を測っているのか」とセットで整理します。
| テスト項目 (何を測る?) | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| コーディング SWE-Bench Pro / 実際のバグ修正 | 69.2% | 64.3% | 58.6% | 54.2% |
| ターミナル操作 Terminal-Bench 2.1 / 黒い画面の操作 | 74.6% | 66.1% | 78.2% | 70.3% |
| 多分野の推論 Humanity's Last Exam / 道具あり | 57.9% | 54.7% | 52.2% | 51.4% |
| コンピューター操作 OSWorld-Verified / 画面をクリック | 83.4% | 82.8% | 78.7% | 76.2% |
| 知識労働 GDPval-AA / 実務タスク (Elo) | 1890 | 1753 | 1769 | 1314 |
| 金融分析 Finance Agent v2 / 財務エージェント | 53.9% | 51.5% | 51.8% | 43.0% |
【公式発表】 注目すべきは 知識労働 (GDPval-AA) の 1890 です。これは「実際の仕事に近いタスク」を AI エージェントにやらせて、人間の評価者が勝敗をつけた Elo スコア (チェスのレーティングと同じ仕組み) です。下のリーダーボードを見ると、Opus 4.8 がすべてのモデルの中で頭ひとつ抜けて 1 位になっています。
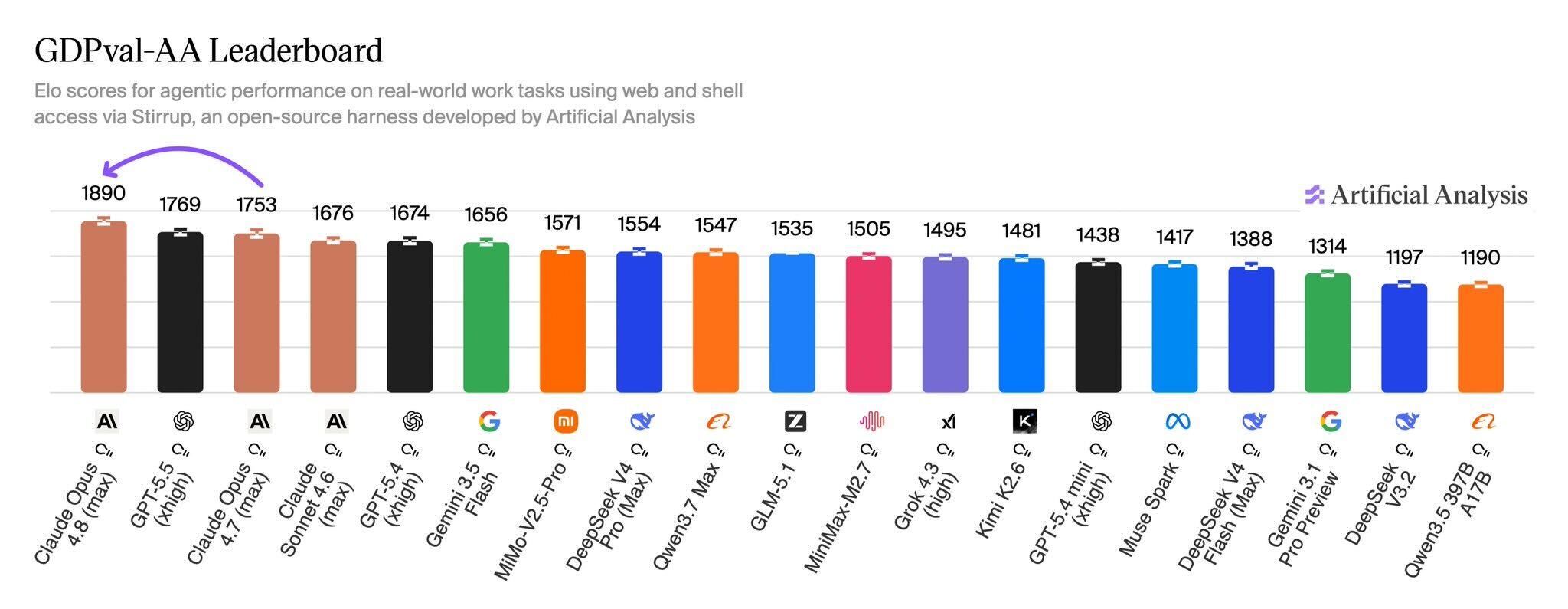
【著者見解】 このグラフのポイントは 2 つです。1 つは Opus 4.8 が 2 位の GPT-5.5 に 121 点差をつけていること (Elo で 100 点差は「だいたい 64% の確率で勝つ」目安)。もう 1 つは、前作 Opus 4.7 (1753) から 137 点も伸びたこと。たった 2 ヶ月でこれだけ動くのは、AI 業界の進化スピードがいかに速いかを表しています。
ただし正直に言うと、Opus 4.8 が全部勝っているわけではありません。ターミナル操作 (Terminal-Bench 2.1) では GPT-5.5 が 78.2% で、Opus 4.8 の 74.6% を上回っています。用途によっては他社モデルのほうが向く場面もある、というのが公平な見方です。
なぜ「正直さ」がそんなに大事なのか? AI を仕事に使ったことがある人なら、一度はこんな経験があるはずです。「資料を作って」と頼んだら、それっぽい数字や出典が並んだ立派な資料が返ってきた。でもよく見るとその数字や出典が存在しなかった——これは「ハルシネーション (hallucination、AI が事実でないことをもっともらしく作る現象)」と呼ばれます。
【公式発表】 Anthropic は Opus 4.8 を「これまでで最も正直 (most honest) なモデル」と位置づけ、具体的には「自分が書いたコードの中の欠陥を、指摘せずに通してしまう確率が、前作 Opus 4.7 の約 4 分の 1 になった」と説明しています。さらに「整合性の取れない (misaligned) ふるまいの割合が大幅に低下し、向社会的な性質 (prosocial traits) の指標で新たな高水準に達した」とされています。
【著者見解】 これを Sales Claw のような業務 AI の立場で噛み砕くと、こういうことです。AI に営業文面を 1,000 通書かせて、人間が全部チェックできないとき、怖いのは「9 割は完璧だけど、1 割にこっそり事実誤認が混ざっていて、AI はそれを完璧だと思い込んでいる」状態です。正直なモデルは「この会社の情報は確証が薄いので確認してください」と自分から赤旗を上げてくれる。これは、AI を「全部おまかせ」ではなく「危ない所だけ人が見る」運用に変える、地味だが決定的な進化です。
ただし【未確認】注意も必要です。「正直になった = もう間違えない」ではありません。「間違いを申告しやすくなった」のであって、間違いそのものがゼロになったわけではありません。Anthropic 自身も「リスクを下げる」表現にとどめており、業務で使うなら最終確認の仕組みは引き続き必須です。
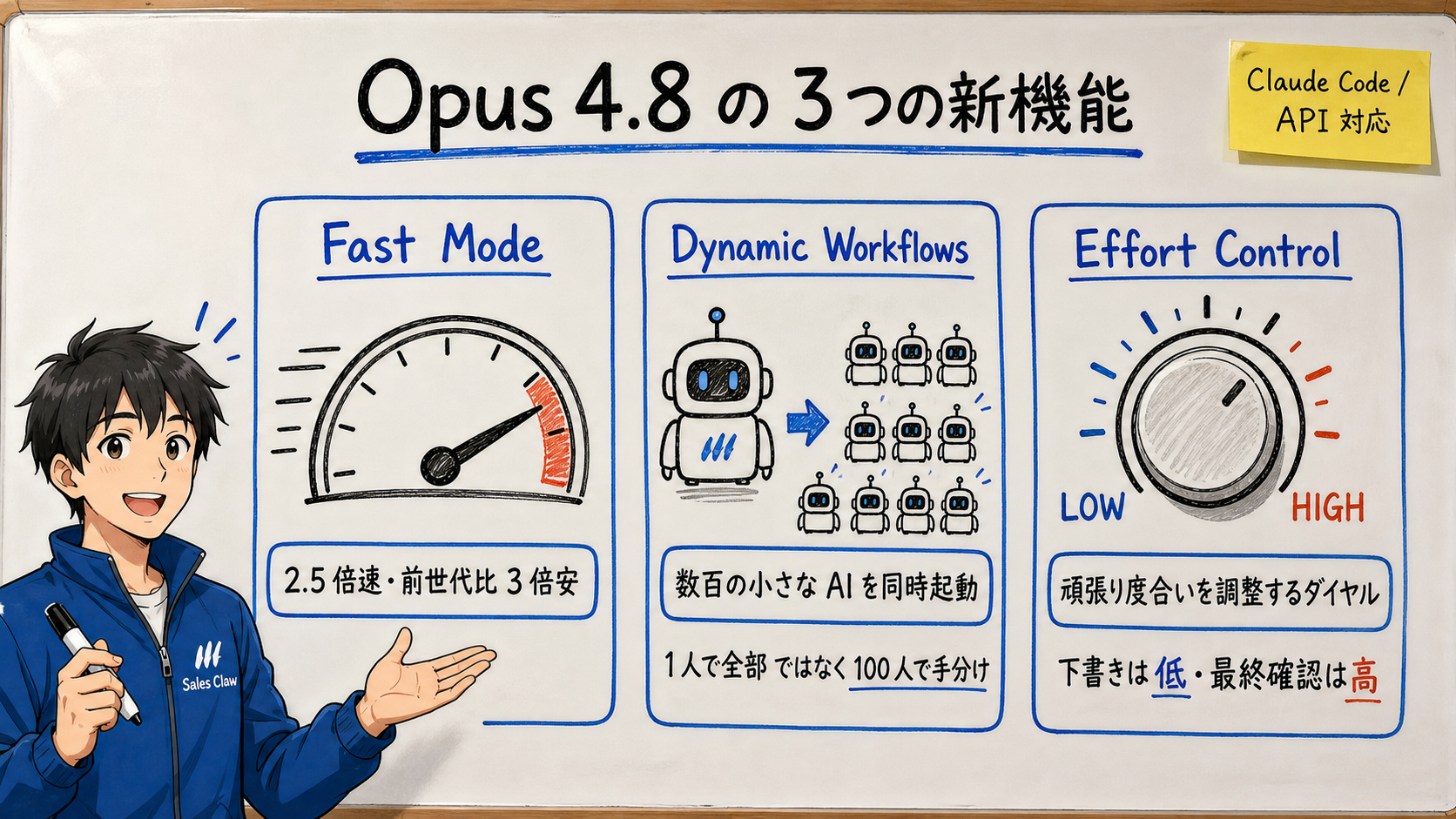
Fast Mode (ファストモード) は、その名の通り「答えを速く返すモード」です。【公式発表】 Opus 4.8 の Fast Mode は標準より 2.5 倍速く動き、前のモデルの高速モードと比べて 3 倍安いとされています。せっかちな作業や、大量のリクエストをさばく場面で効きます。
Dynamic Workflows (ダイナミック・ワークフロー) は、1 つの大きな仕事を、数百個の小さな AI (サブエージェント / subagent) に分担させて、同時に走らせる仕組みです。【公式発表】 Anthropic は Claude Code (クロードコード、開発者向けのコマンドライン版 Claude) で「数百のサブエージェントを動かして結果をまとめる」機能としてこれを紹介しています。
身近なたとえで言うと、「1 人の優秀な社員に全部やらせる」のではなく「100 人のアルバイトに 1 マスずつ調べさせて、最後に集計する」働き方です。「1,000 社のリストをそれぞれ調べる」ような横に広い作業では、時間が劇的に短くなります。
Effort Control (エフォート・コントロール) は、「この作業にはどれだけ手間をかけて考えてほしいか」を人間が指定できる機能です。【公式発表】 ブラウザ版 Claude でも Claude Code でも、「じっくり考えてほしい作業には effort を高く、サッと終わらせたい作業には低く」と調整できます。
【著者見解】 これは地味ですが実用的です。AI は「頑張る = 時間とお金がかかる」ので、全部の作業に全力を出されると無駄が多い。「下書きはサッと、最終チェックはじっくり」と使い分けられるのは、コスト管理の観点でとても大きい。あわせて、開発者向けには Messages API に system entries (作業の途中で指示を差し込んでも、それまでの処理を無駄にしない仕組み) も追加されました。
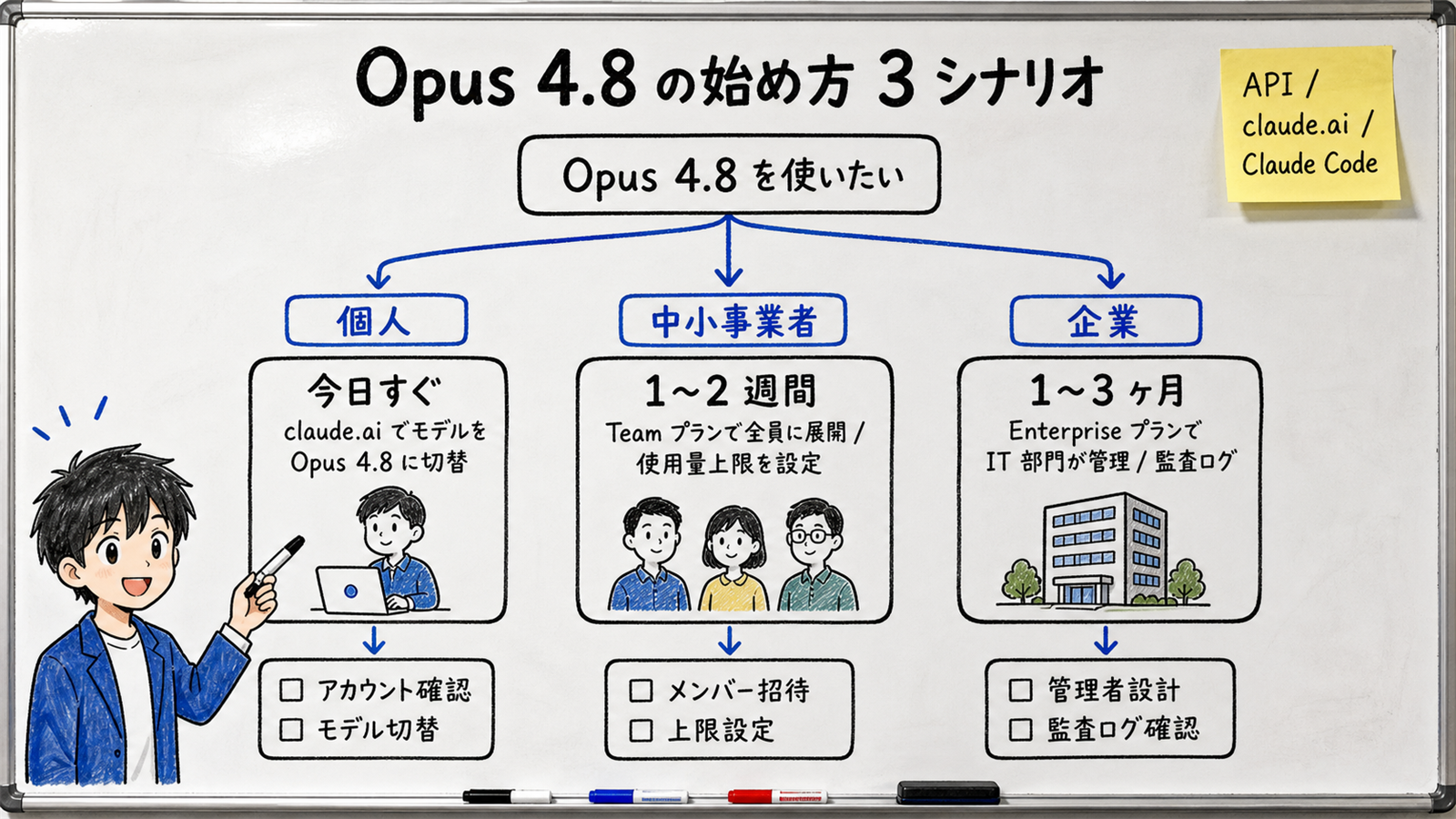
【公式発表】 Opus 4.8 は発表と同時に、API (モデル名 claude-opus-4-8)・ブラウザ版 claude.ai・Claude Code で使えるようになりました。プランは Enterprise / Team / Max で利用可能です。
いちばん手軽なのは、すでに Claude を使っている人です。claude.ai を開いて、画面のモデル選択メニューから Opus 4.8 を選ぶだけ。料金プラン (Max など) に入っていれば追加費用なく切り替えられます。まずは「いつもの作業を Opus 4.8 でもう一度やらせて、違いを体感する」のがおすすめです。
従業員 10〜100 名規模なら、Team プランを契約して社員に配ります。導入時にやるべきことは 3 点: (1) 使用量上限をユーザー単位で設定する、(2) 用途別にルールを決める (どの業務に使ってよいか)、(3) 成果物の確認フローを決める。「正直なモデルだから確認不要」ではなく「正直なモデルだからこそ、赤旗が立った所を人が見る」運用にします。
従業員 500 名以上なら、Enterprise プランで IT 部門・法務・セキュリティ部門を巻き込んで段階展開します。【著者見解】 同時期に Claude Compliance API と 28 統合パートナー が発表されているように、業界は「AI を SaaS と同じ管理枠に乗せる」方向に動いています。監査ログ・権限管理・データ越境の確認を最初から設計に組み込むのが推奨です。
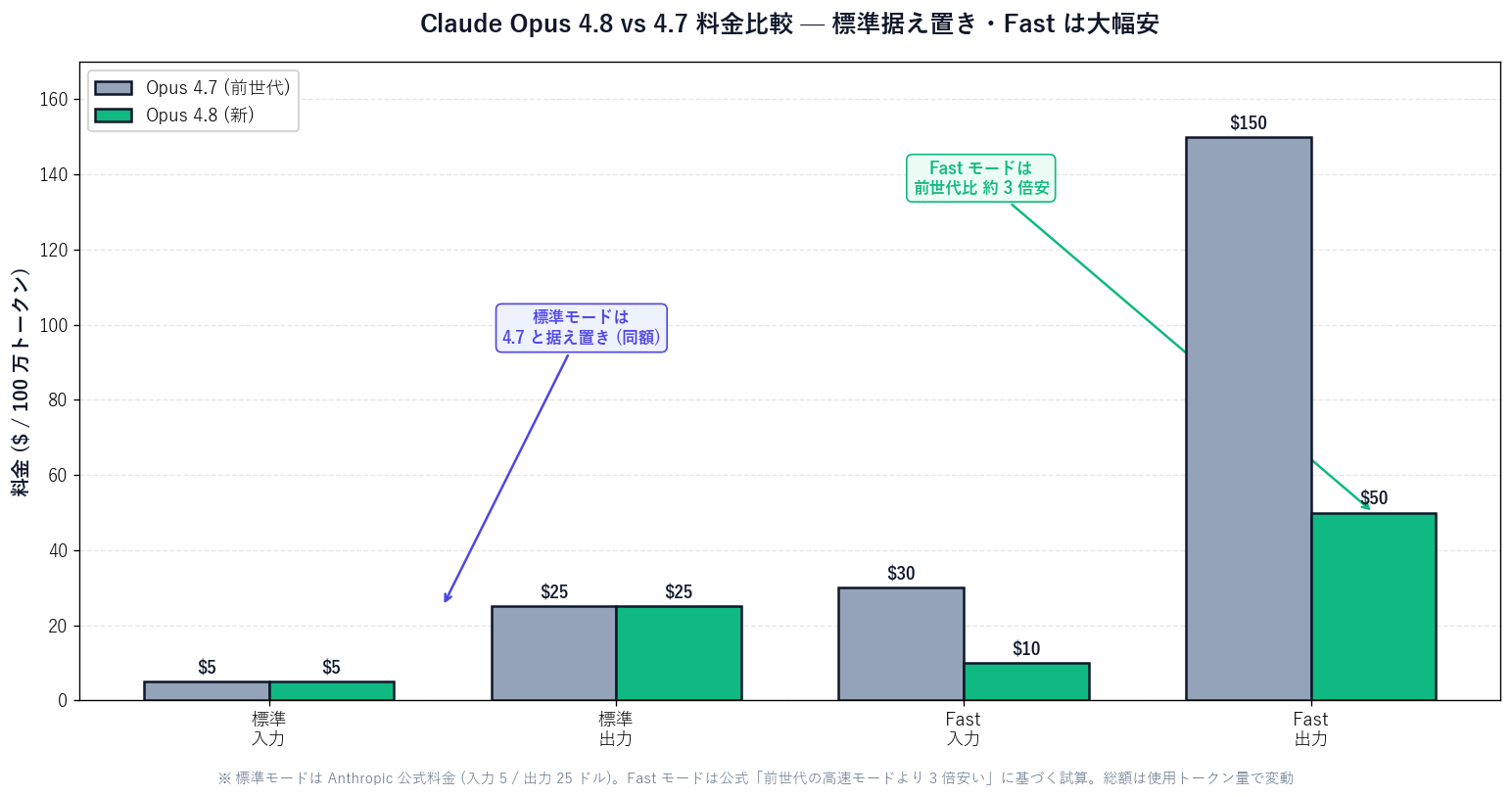
【著者見解】 ここが一般の方が誤解しやすいポイントです。「料金単価が同じ = 月の請求も同じ」ではありません。Opus 4.8 は「より長く自律的に働ける」「数百の並列処理ができる」ので、同じ料金単価でも、消費するトークン量 (= 仕事量) が増えれば総額は上がります。
現に、Claude を全社展開したライドシェア大手 Uber は、2026 年 AI 予算を 4 ヶ月で使い切ったと報じられました (CTO が The Information に認めた)。新機能の Dynamic Workflows で数百の AI を走らせれば、便利な分だけ請求も伸びます。対策は「導入と同時に使用量上限を仕込む」こと。これは前回の Codex Goal Mode の記事でも書いた、自律 AI 時代の鉄則です。
| 項目 | 料金単価だけ見た誤解 | 実際に起きること |
|---|---|---|
| 単価 | 4.7 と同じ ($5 / $25) | 同じ (ここは正しい) |
| 1 タスクの仕事量 | 変わらないと思いがち | 自律で長く働く分、増えやすい |
| 並列処理 | 意識しない | Dynamic Workflows で数百倍に |
| 月の総額 | 据え置きだと思い込む | 使い方次第で膨らむ |
| 対策 | 特になし | 使用量上限・effort 調整・監査 |
【著者見解】 皮肉なことに、「正直なモデル」という売り文句こそが最大のリスク源になりえます。「正直なら任せきっていい」と人間が油断すると、AI が赤旗を立てた数少ないケースさえ見落とすからです。正直さは「人が見るべき所を教えてくれる地図」であって、「人が見なくていい免罪符」ではありません。
Opus 4.8 を営業フォーム送信・カスタマーサポート返信のような外部接触業務に使う場合、日本では以下の法令への適合確認が必要です。
【著者見解】 Opus 4.8 はあくまで道具なので、これらの法令適合 (コンプライアンス) は使う側の責任です。とくにエンタープライズ用途では、誰がいつ何を送ったかを後から追える体制まで含めて設計する必要があります。モデルが賢く正直になっても、「何を送ってよいか」の判断責任は人間と運用設計に残ります。
ここから先は、Sales Claw 開発者として「Opus 4.8 を実際に営業業務に組み込むなら何が必要か」を実装目線で書きます。
Sales Claw は、ポリシー制御・送信前自動検査・営業 NG 検出・CAPTCHA 検出時停止・送信頻度制限・監査ログ保存・自動停止条件によって、誤送信と規約違反リスクを下げる設計の OSS ツールです。Opus 4.8 が「正直に赤旗を立てる」のと、Sales Claw が「危ない送信を自動で止める」のは、同じ "全部おまかせにしない" 思想の両輪です。
【personal_metric】 私 (中澤) は Sales Claw の自律ループ設計を 過去 90 日で 3 回書き直しました。1 回目は終了条件なしで暴走、2 回目は件数だけ指定して時間超過、3 回目でようやく「件数 × 時間 × ターン上限の AND」で安定。Opus 4.8 がいくら正直で賢くなっても、「いつ止まるか」を設計するのは人間の仕事だという確信は変わりません。
Opus 4.8 が「ここは自信がない」と申告してくれるなら、その赤旗を拾って自動で止める仕組みを業務側に用意するのが筋です。Sales Claw では、AI が判断に迷った送信は awaiting_approval 状態にして監査ログに残し、自動では送らない設計にしています。「正直なモデル」+「正直さを受け止める運用」の組合せで、はじめて事故が減ります。
自律ループには必ず複数の終了条件を AND でかけ、AI が自律実行した結果は必ず監査ログ (action-log.json) に時系列で記録し、外部送信の前には送信前自動検査を通す。モデルが Opus 4.7 から 4.8 に上がっても、この 3 点セットの重要性は変わりません。むしろ「より長く・より並列に」働けるようになったぶん、止め方と記録の設計はこれまで以上に大事になります。
2026 年 5 月 28 日に登場した Claude Opus 4.8 は、「賢さ」だけでなく「正直さ」を前面に出した節目のモデルです。6 項目中 5 項目で他社・前作を上回り、知識労働では全モデル中トップの 1890 を記録。料金は据え置きのまま、Fast Mode は 3 倍安く、Dynamic Workflows と Effort Control という新しい使い方が加わりました。
一方で「正直で賢い AI」も、任せきれば事故ります。正直さは「人が見るべき所を教えてくれる地図」であって免罪符ではない。料金単価が据え置きでも総額は膨らむ。賢くなったぶん、任せる範囲と止め方の設計が一層大事になる——これが Sales Claw 開発者としての率直な見立てです。
Opus 4.8 を業務に入れる前に
次のアクション: まず claude.ai でモデルを Opus 4.8 に切り替え、いつもの作業を 1 つやらせて違いを体感してください。営業・サポート業務に AI を入れたい方は、Sales Claw のような業務特化 OSS の クイックスタートガイド から始められます。
本記事の続編として、Anthropic が OpenAI を初めて逆転した業界トレンド整理もあわせてどうぞ。
本記事は X 公式アカウントと公式ドキュメントを一次情報として参照しています。