AIニュース
Claude Compliance API Launches — Anthropic Wires Claude into 28 Security Tools, Bringing AI Under the Same Governance Frame as Every Other SaaS
15 分
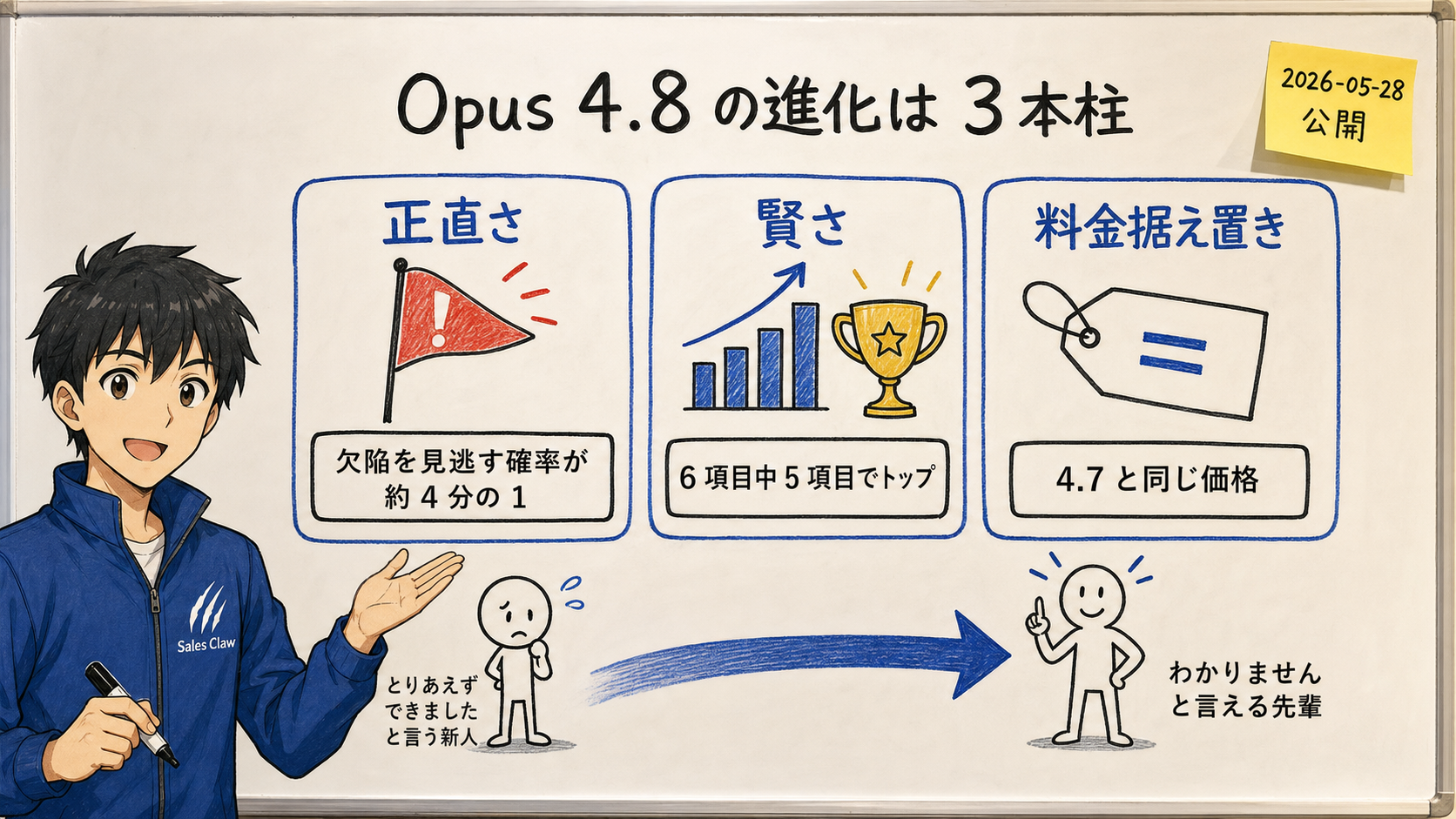
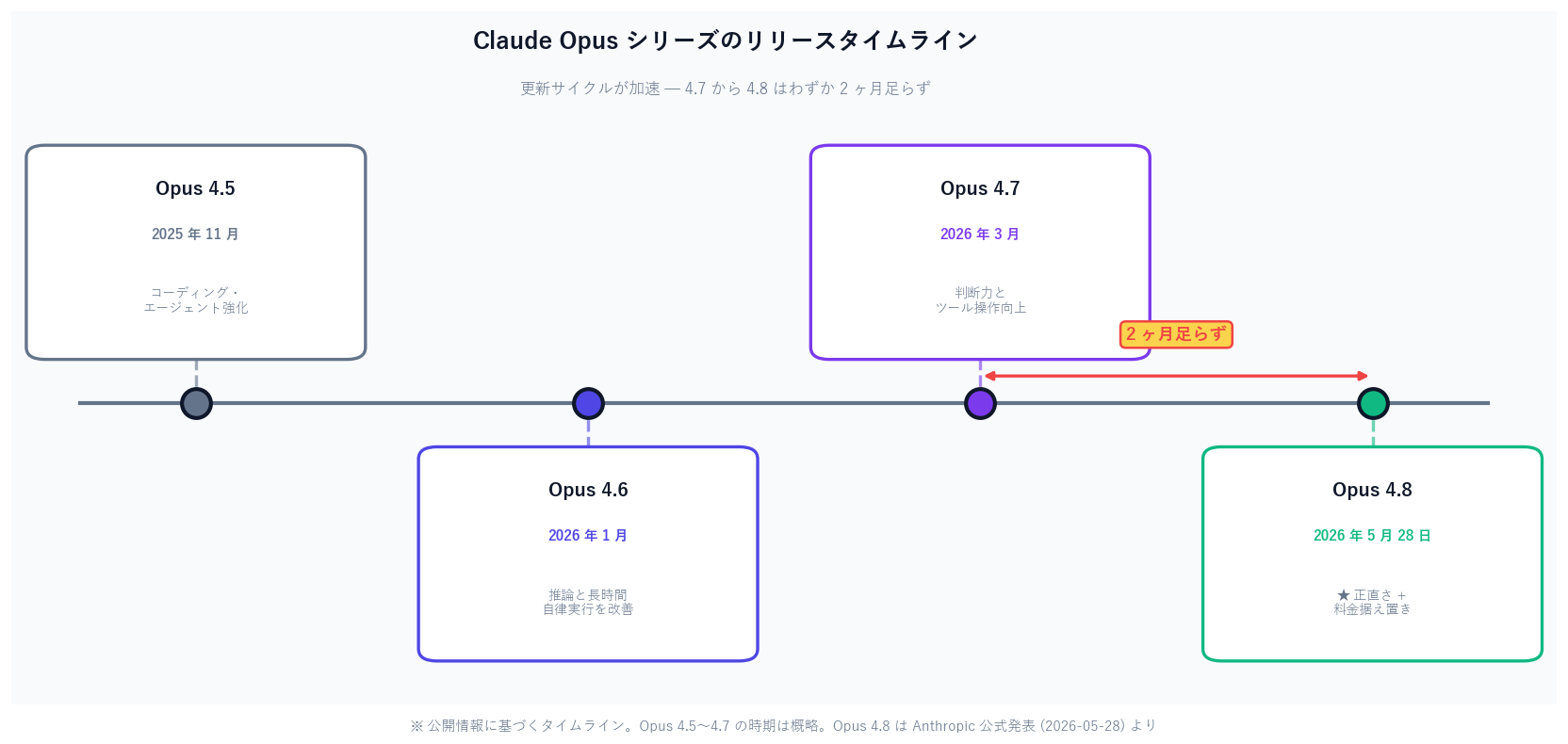
On May 28, 2026, Anthropic released its flagship model Claude Opus 4.8 — less than two months after 4.7. The real story this time is not raw intelligence but "honesty": the chance it silently lets flaws in its own code through dropped to roughly a quarter. This article walks general readers through the actual numbers across six official benchmarks, the cost trap hiding behind "flat pricing," the three new features (Fast Mode / Dynamic Workflows / Effort Control), and how individuals, SMBs, and enterprises should get started — framed with the metaphor of a new hire growing into a senior colleague.

中澤 圭志
@keishi_nakazawaSales Claw maintainer

Key Facts
Release date
2026-05-28 (less than two months after Opus 4.7)
Biggest leap
honesty — chance of missing code flaws dropped to about one quarter
Knowledge work (GDPval-AA)
1890, top of all models (121 points ahead of #2 GPT-5.5)
Pricing
$5 input / $25 output (per 1M tokens), unchanged from 4.7
In one sentence
On May 28, 2026, Anthropic (the AI company behind "Claude," a rival to ChatGPT) released its new flagship model, Claude Opus 4.8 — barely two months after Opus 4.7. There are two headline changes. First, the model "honestly flags the rough edges in its own work" (it is roughly 4× less likely to silently let a flaw in its own code slip through). Second, "the price stayed flat while the intelligence went up." On top of that, a Fast Mode that is 3× cheaper than the previous fast mode, "Dynamic Workflows" that run hundreds of small AIs at once, and "Effort Control" that dials how hard the AI works all arrived. For readers who are not deep in AI, we lay out what got better and how it matters to ordinary people and small businesses, using the metaphor of a new hire and a senior colleague.
Bottom line: The single biggest leap in Opus 4.8 is not its intelligence (benchmark scores) but its "honesty." Previous AIs would often say "Done!" with total confidence while actually being wrong. Opus 4.8 now volunteers "I'm not confident here" or "please double-check this part" on its own, and according to Anthropic it is roughly 4× less likely to silently pass off a flaw in code it wrote. This pays off precisely in the situations where a human cannot check every single output (overnight automation, bulk form submission, and the like). At the same time, you still need to remember that "became honest" is not the same as "became perfect," and that misreading the pricing model can make costs balloon.
"How is Opus 4.8 different from 4.7?" "What does an ‘honest AI’ even mean?" "Does this matter to a small business like mine?" — this article answers those three questions about Claude Opus 4.8, announced on May 28, 2026, drawing on Anthropic's official "Introducing Claude Opus 4.8" and the independent benchmark house Artificial Analysis's GDPval-AA leaderboard as primary sources, from the perspective of a Sales Claw maintainer.
As an aside: the AI writing this article is itself Claude Opus 4.8.The human behind it (Nakazawa) said "I'm going to write an article about you" and had it do the work. Writing about oneself objectively is a little awkward, but we'll proceed without exaggeration, using only numbers that can be officially verified.
Companion reads: Anthropic overtakes OpenAI for the first time — industry trend roundup, OpenAI Codex's Goal Mode reaches general availability, and Claude Compliance API and 28 integration partners explained.
This article uses Anthropic's official "Introducing Claude Opus 4.8" / Anthropic Models official docs / Anthropic Pricing official docs as primary sources. The benchmark comparison uses Anthropic's official table and the Artificial Analysis leaderboard. Sales Claw's free download page is also available.
First, the basics: Claude is a conversational AI built by Anthropic. It is a rival to ChatGPT (OpenAI) and Gemini (Google). Claude comes in three sizes, ordered by intelligence and price: Opus (top tier) > Sonnet (mid tier) > Haiku (lightweight). What got updated this time is the one at the top, Opus.
Let's translate three important terms into plain language up front.
| Jargon | In plain words | Everyday analogy |
|---|---|---|
| Benchmark | A shared test that measures how smart an AI is | A mock-exam score — everyone solves the same problems and gets ranked |
| Honesty (alignment) | How much the AI avoids "pretending it's done when it isn't" | A new hire who doesn't lie "Finished!" and instead says "I'm not sure here" |
| Agentic | The AI uses tools on its own and runs multiple steps by itself | A secretary who, given one instruction, does the research and the execution |
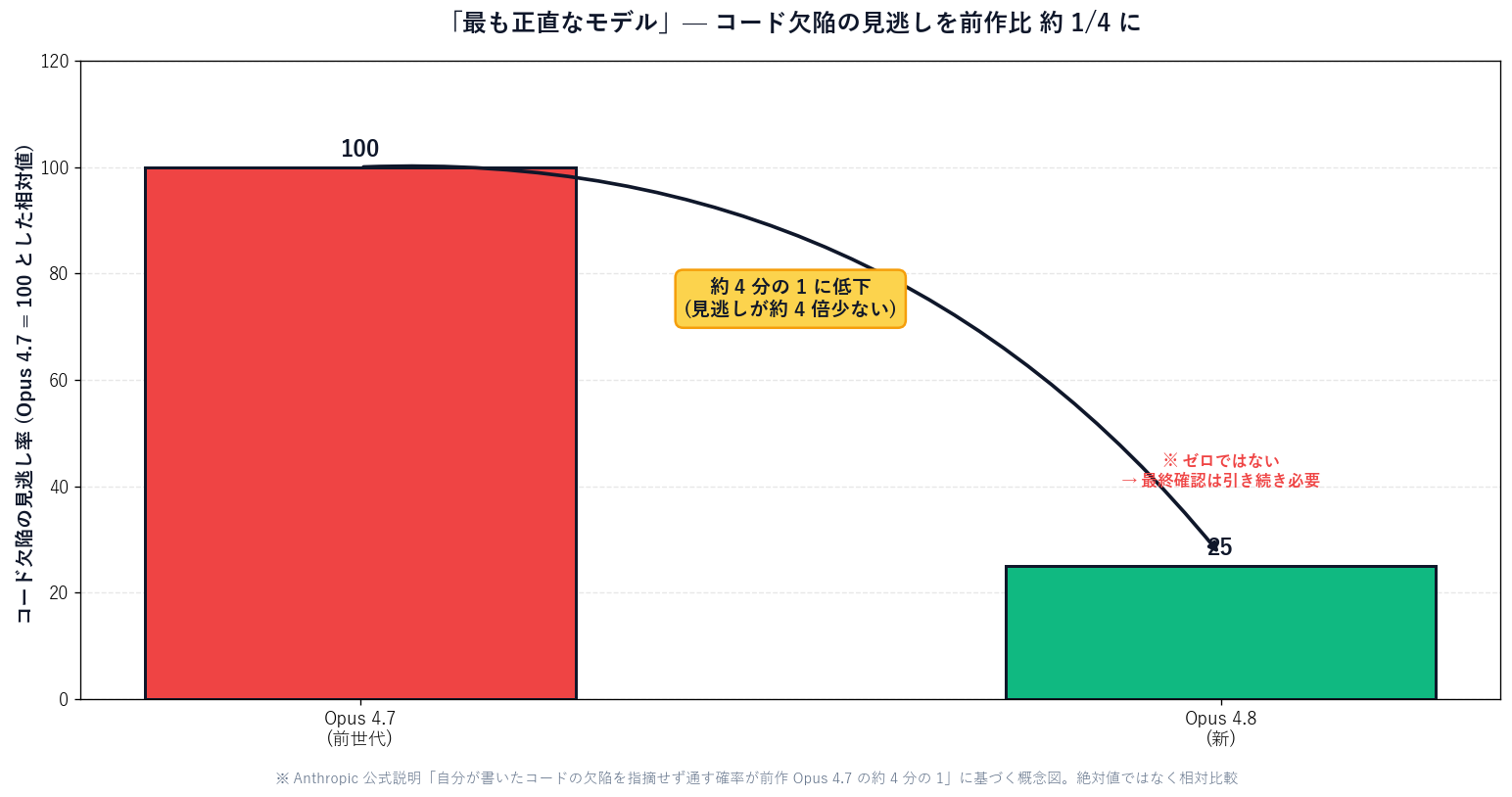
[Official] Anthropic describes Opus 4.8 as having "sharper judgement, more honesty about its progress, and the ability to work independently for longer than its predecessors." Early testers report that it is "more likely to flag uncertainty about its own work and less likely to make unsupported claims," and that it is roughly one-quarter as likely as its predecessor to silently pass off a flaw in code it wrote.
[Author's view] In a Sales Claw maintainer's terms, this is the change from "a new hire who just says ‘done’" into "a senior who can properly say ‘I don't know’ about the parts they don't know." The scariest thing about putting AI into your workflow is not that it's unintelligent — it's that it's confidently wrong.In overnight jobs and bulk sends where a human cannot check everything, this "honesty" becomes the last line of defense against accidents.
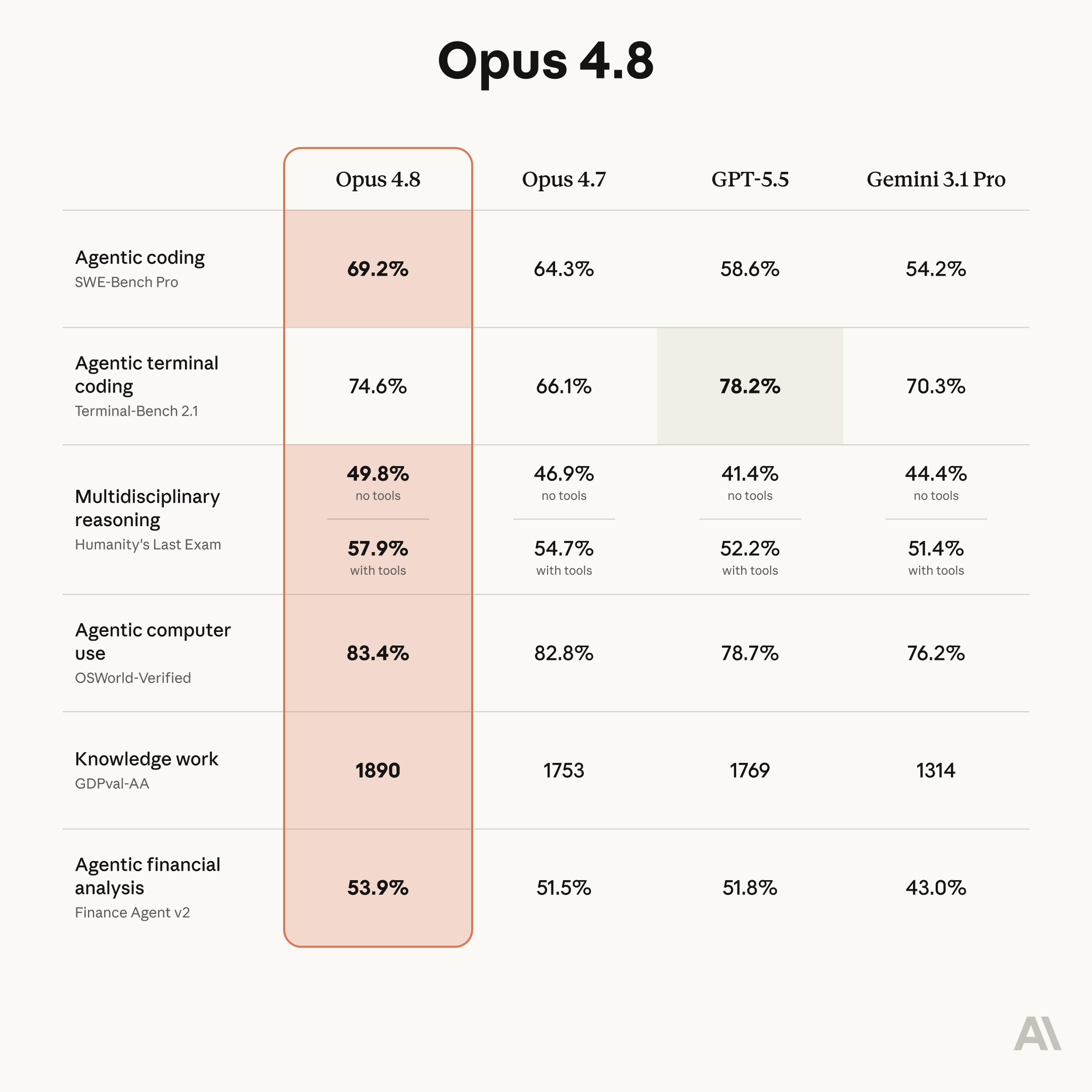
The comparison table Anthropic published in its announcement is the image above. To make it readable for general audiences, we lay out the six categories together with "what each one measures."
| Test (what it measures) | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Coding SWE-Bench Pro / real bug fixes | 69.2% | 64.3% | 58.6% | 54.2% |
| Terminal use Terminal-Bench 2.1 / the black screen | 74.6% | 66.1% | 78.2% | 70.3% |
| Cross-domain reasoning Humanity's Last Exam / with tools | 57.9% | 54.7% | 52.2% | 51.4% |
| Computer use OSWorld-Verified / clicking the screen | 83.4% | 82.8% | 78.7% | 76.2% |
| Knowledge work GDPval-AA / real-world tasks (Elo) | 1890 | 1753 | 1769 | 1314 |
| Financial analysis Finance Agent v2 / finance agent | 53.9% | 51.5% | 51.8% | 43.0% |
[Official] The number to watch is knowledge work (GDPval-AA) at 1890.This is an Elo score (the same mechanism as chess ratings) in which AI agents perform "tasks close to real work" and human raters decide the winners. In the leaderboard below, Opus 4.8 stands a head above all other models at #1.
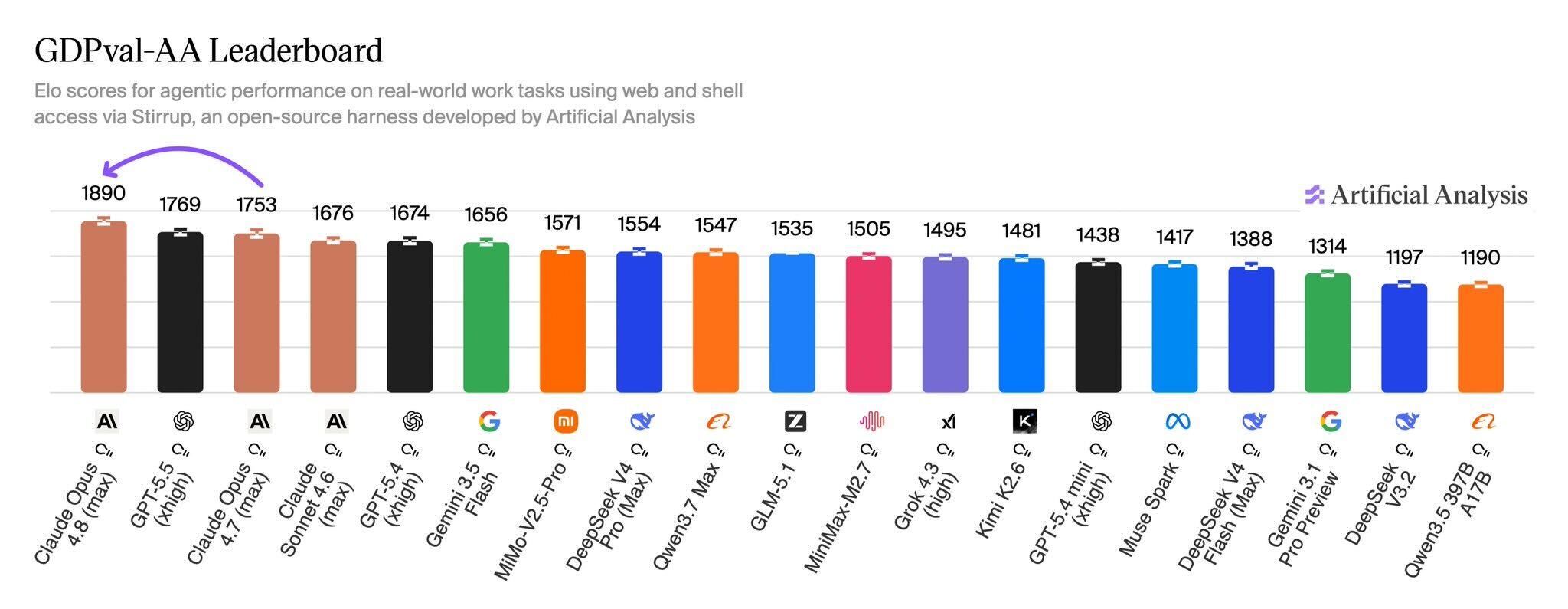
[Author's view] Two things stand out in this chart. First, Opus 4.8 is 121 points ahead of #2 GPT-5.5 (in Elo, a 100-point gap roughly means "wins about 64% of the time"). Second, it jumped 137 points from its predecessor Opus 4.7 (1753). Moving this much in just two months shows how fast the AI industry is evolving.
That said, to be honest, Opus 4.8 does not win everything. On terminal use (Terminal-Bench 2.1), GPT-5.5 leads at 78.2%, above Opus 4.8's 74.6%. The fair view is that for some use cases, a rival model may be the better fit.
Why does "honesty" matter so much? Anyone who has used AI for work has probably had this experience: you ask it to "make a document," and back comes a polished doc full of plausible-looking numbers and citations. But on closer inspection, those numbers and citations didn't exist— this is called "hallucination" (an AI fabricating something untrue in a believable way).
[Official] Anthropic positions Opus 4.8 as "the most honest model to date," and concretely states that "the chance it passes off a flaw in code it wrote, without flagging it, is roughly one-quarter that of its predecessor Opus 4.7."It further says that "the rate of misaligned behavior dropped significantly, and it reached a new high on indicators of prosocial traits."
[Author's view] Broken down from the standpoint of a business AI like Sales Claw, it means this. When you have an AI write 1,000 sales messages and a human cannot check all of them, the scary state is "90% are perfect, but 10% quietly contain factual errors — and the AI believes they're all perfect." An honest model raises a red flag on its own: "the information on this company is weakly substantiated; please verify." This is a modest but decisive evolution that turns AI use from "hand it everything" into "a human only looks at the dangerous parts."
That said, [Unverified] a caveat is needed too. "Became honest" does not mean "won't make mistakes anymore." It became more likely to flag mistakes; the mistakes themselves did not drop to zero. Anthropic itself only goes as far as "reduces risk," so if you use it in production, a final-check mechanism remains mandatory.
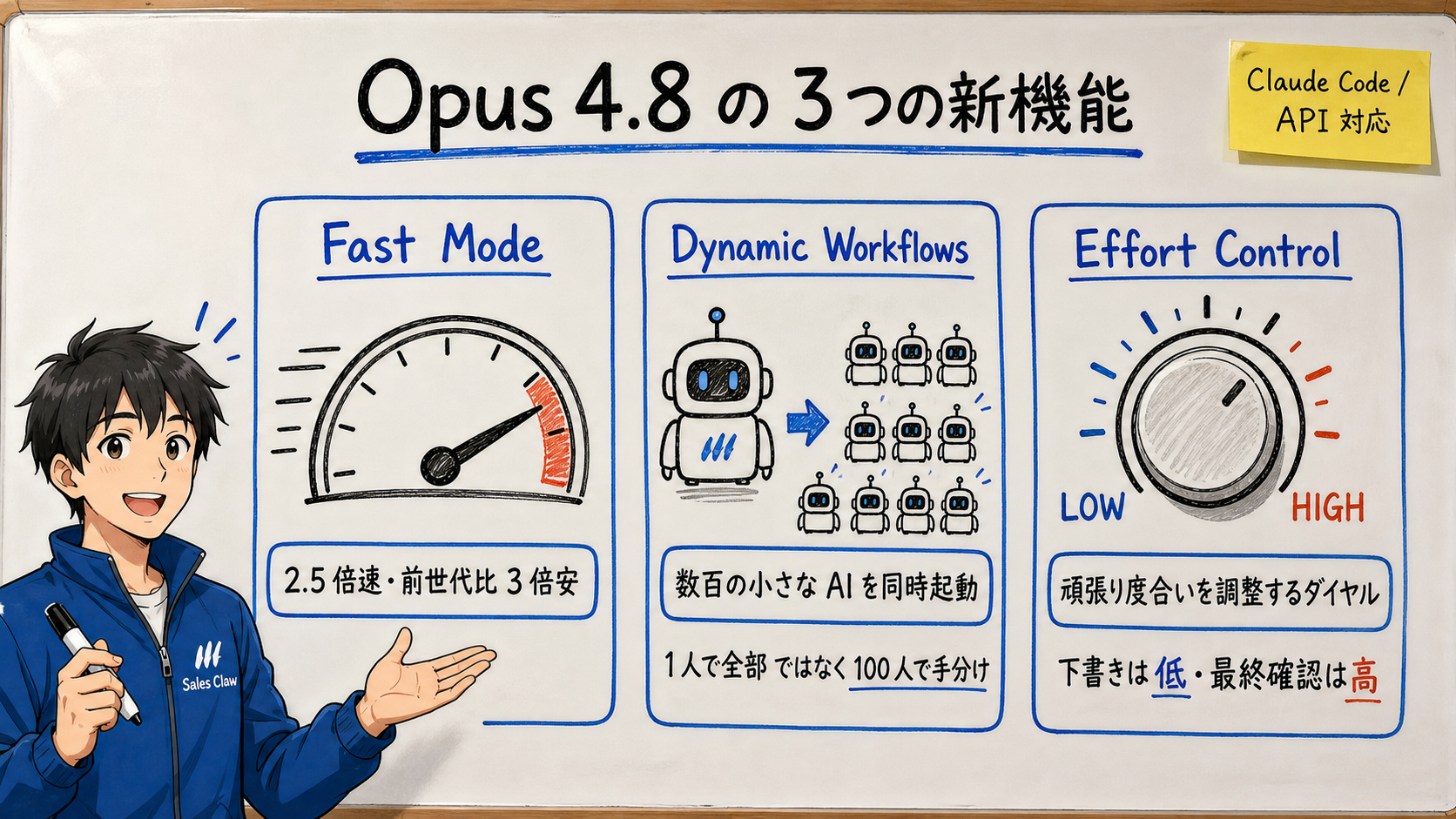
Fast Mode is, as the name says, a "return answers fast" mode. [Official] Opus 4.8's Fast Mode is said to run 2.5× faster than standard and to be 3× cheaper than the previous model's fast mode. It shines on impatient work and on handling large volumes of requests.
Dynamic Workflows is a mechanism that splits one big job among hundreds of small AIs (sub-agents) and runs them at the same time. [Official]Anthropic introduces this in Claude Code (the developer-facing command-line version of Claude) as a feature that "runs hundreds of sub-agents and aggregates the results."
In everyday terms, it's the difference between "having one excellent employee do everything" and "having 100 part-timers each check one square, then tallying at the end." For horizontally wide worklike "research each of 1,000 companies," the time drops dramatically.
Effort Control lets a human specify "how much effort do you want it to spend thinking about this task." [Official] In both browser Claude and Claude Code, you can set effort high for work you want it to think hard about, and low for work you want done quickly.
[Author's view] This is unglamorous but practical. Because for AI "trying hard = time and money," spending full effort on everything is wasteful. Being able to use "quick for drafts, thorough for the final check" is huge for cost management. For developers, system entries (a mechanism in the Messages API that lets you inject instructions mid-task without wasting the work done so far) were also added.
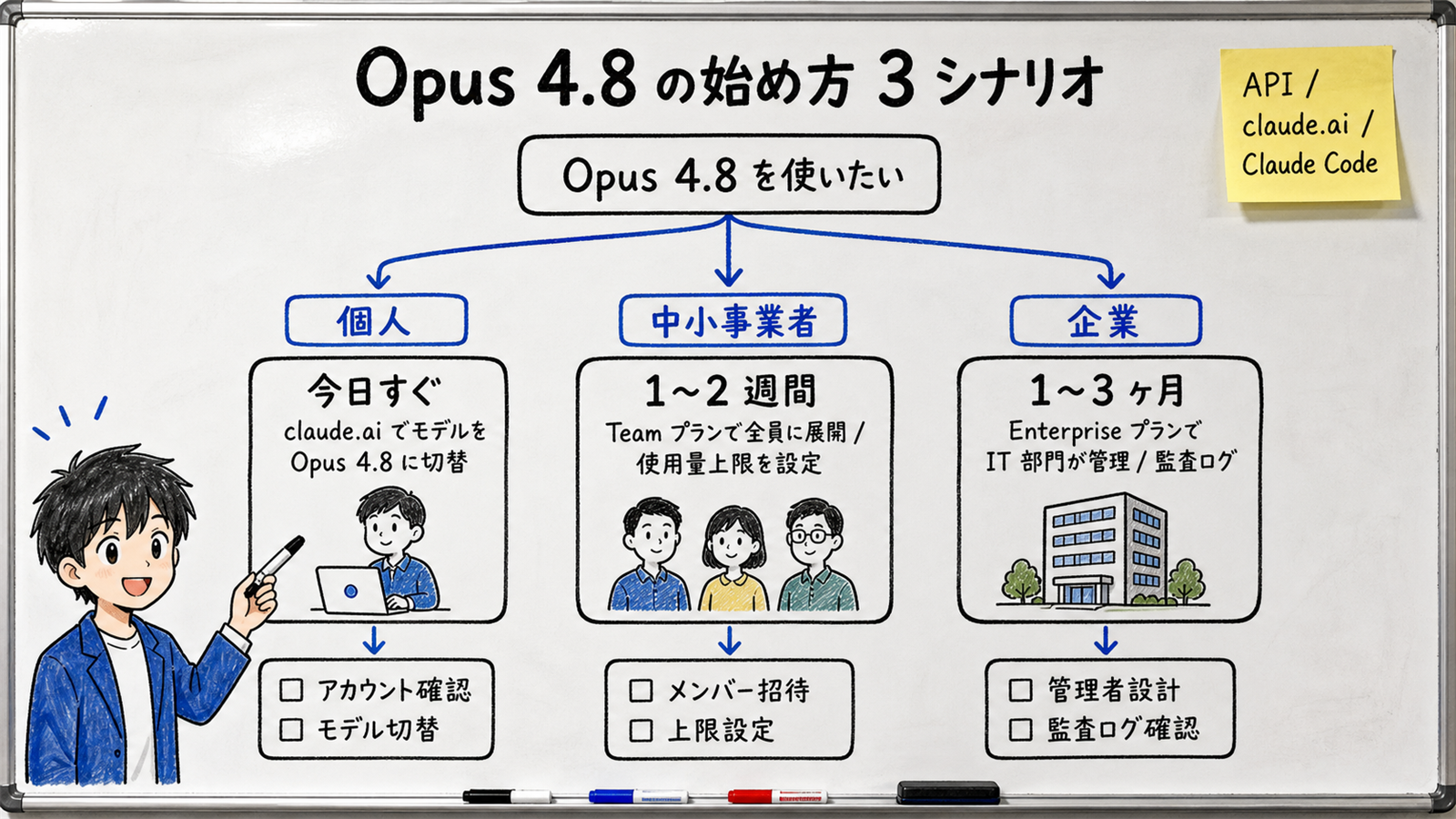
[Official] At launch, Opus 4.8 became usable via the API (model name claude-opus-4-8), the browser at claude.ai, and Claude Code. It is available on the Enterprise / Team / Max plans.
The easiest path is for people already using Claude. Open claude.ai and pick Opus 4.8 from the model menu. If you're on a paid plan (such as Max), you can switch at no extra cost. The recommended first step is to "re-run your usual work with Opus 4.8 and feel the difference."
For 10–100 employees, sign up for the Team plan and distribute it to staff. Three things to do at rollout: (1) set usage limits per user, (2) decide rules by use case (which tasks are allowed), and (3) decide a deliverable-review flow.Don't treat it as "an honest model, so no review needed" — make it "an honest model, so a human looks at the parts where it raised a red flag."
For 500+ employees, roll out in phases on the Enterprise plan, involving IT, legal, and security teams. [Author's view] As the contemporaneous announcement of the Claude Compliance API and 28 integration partnersshows, the industry is moving to "put AI in the same management envelope as SaaS." The recommendation is to design audit logging, access control, and data-residency checks into the rollout from the start.
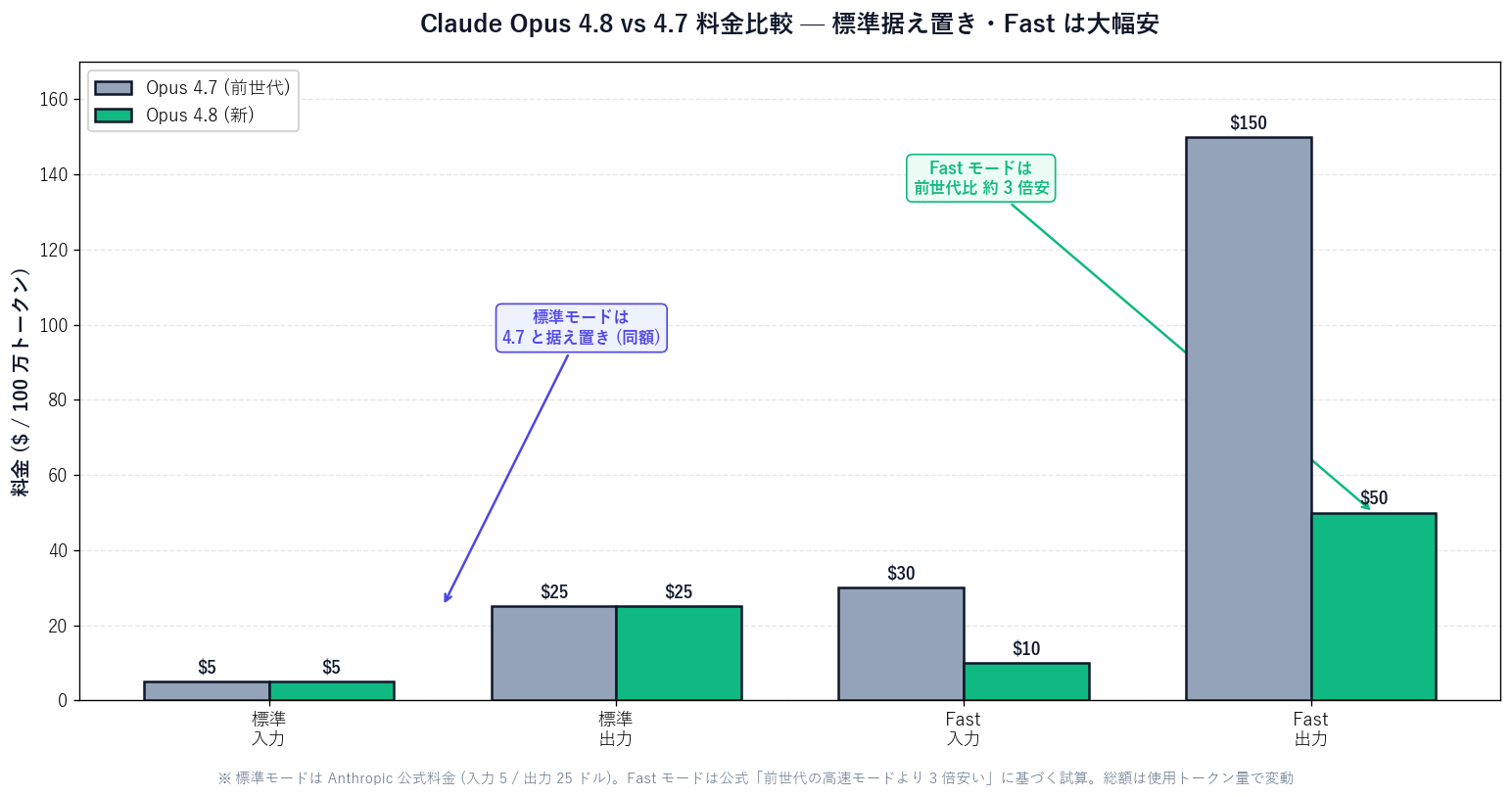
[Author's view] This is the point general readers most easily misread. "Same unit price = same monthly bill" is not true. Because Opus 4.8 can "work autonomously for longer" and "run hundreds of parallel jobs," even at the same unit price, the total rises as token consumption (= amount of work) increases.
Indeed, the ride-hailing giant Uber, which deployed Claude company-wide, was reported to have burned through its 2026 AI budget in four months (its CTO admitted as much to The Information). Run hundreds of AIs with the new Dynamic Workflows, and the bill grows with the convenience. The countermeasure is to "build in usage limits at the same time you deploy." This is the iron rule of the autonomous-AI era, as covered in the previous Codex Goal Mode article.
| 項目 | Misreading only the unit price | What actually happens |
|---|---|---|
| Unit price | Same as 4.7 ($5 / $25) | Same (this part is correct) |
| Work per task | Assumed unchanged | Tends to rise as it works autonomously for longer |
| Parallelism | Not considered | Hundreds of times with Dynamic Workflows |
| Monthly total | Assumed flat | Balloons depending on usage |
| Countermeasure | None in particular | Usage limits, effort tuning, auditing |
[Author's view] Ironically, the "honest model" tagline itself can become the biggest source of risk. When humans relax with "if it's honest, we can hand it everything," they miss even the few cases where the AI did raise a red flag. Honesty is "a map showing where a human should look," not "a free pass for a human not to look."
When you use Opus 4.8 for external-facing work such as sales form submission or customer-support replies, in Japan you need to verify compliance with the following laws.
[Author's view]Opus 4.8 is just a tool, so this legal compliance is the responsibility of the user. For enterprise use in particular, the design must extend all the way to a system that can later trace who sent what and when. Even as the model becomes smart and honest, the responsibility for "what may be sent" remains with humans and operational design.
From here on, as a Sales Claw maintainer, I'll write from an implementation standpoint about what's needed to actually build Opus 4.8 into sales work.
Sales Claw is an OSS tool designed to lower mis-send and ToS-violation risk through policy control, pre-send automated inspection, sales-NG detection, stop-on-CAPTCHA, send-rate limits, audit-log retention, and auto-stop conditions. Opus 4.8 "raising a red flag honestly" and Sales Claw "automatically stopping dangerous sends" are the two wheels of the same "don't hand it everything" philosophy.
[personal_metric] I (Nakazawa) rewrote Sales Claw's autonomous-loop design three times in the past 90 days. The first had no stop condition and ran away; the second specified only a count and overran on time; the third finally stabilized with an AND of "count × time × turn cap." However honest and smart Opus 4.8 gets, my conviction that "designing when to stop is a human's job"hasn't changed.
If Opus 4.8 will tell you "I'm not confident here," it's only sensible to build a mechanism on the operations side that catches that red flag and stops automatically. In Sales Claw, a send the AI is unsure about is set to awaiting_approval, kept in the audit log, and never sent automatically. Only the combination of an "honest model" plus "operations that receive the honesty" reduces accidents.
Always apply multiple stop conditions with AND to an autonomous loop, always record the results of autonomous runs chronologically in the audit log (action-log.json), and put external sends through pre-send automated inspection.Whether the model goes from Opus 4.7 to 4.8, the importance of this three-piece set doesn't change. If anything — because it can now work "longer and more in parallel" — designing the stop and the record matters more than ever.
Claude Opus 4.8, which arrived on May 28, 2026, is a milestone model that foregrounds not just "intelligence" but "honesty." It beats rivals and its predecessor in 5 of 6 categories and records the top score among all models in knowledge work at 1890. Pricing stayed flat, Fast Mode is 3× cheaper, and the new ways of working — Dynamic Workflows and Effort Control — were added.
At the same time, even an "honest, smart AI" will cause accidents if you hand it everything.Honesty is "a map showing where a human should look," not a free pass. The total balloons even at flat unit pricing. The smarter it gets, the more the design of scope and stop conditions matters — that's my candid read as a Sales Claw maintainer.
Before putting Opus 4.8 into production
Next action: first switch the model to Opus 4.8 at claude.ai and have it do one of your usual tasks to feel the difference. If you want to bring AI into sales or support work, you can start from the quick-start guide of a business-focused OSS like Sales Claw.
As a follow-up to this article, see also Anthropic overtakes OpenAI for the first time — industry trend roundup.
本記事は X 公式アカウントと公式ドキュメントを一次情報として参照しています。
この記事の著者
中澤 圭志
Sales Claw maintainer
Designs and develops Sales Claw. Writes from the field on B2B sales automation and applied AI.