AIニュース
Claude Opus 4.8 は "正直な AI" になった — ベンチマーク・新機能・コストを一般向け解説
15 分
2026-05-18 公開の Cursor Composer 2.5。Moonshot Kimi K2.5 checkpoint を起点に合成 RL タスクを 25 倍に拡張し、SWE-Bench Multilingual で Opus 4.7 / GPT-5.5 と並ぶ性能を約 1/10 のコストで提供。Cursor 公式 Blog / Changelog / Forum を一次情報に、ベンチマーク・アーキテクチャ・価格戦略・long-horizon 改善・API 非公開リスク・Sales Claw 視点での targeted RL 示唆まで整理する。

中澤 圭志
@keishi_nakazawaSales Claw 開発者
Key Facts
リリース日
2026-05-18 (米国時間、Cursor 公式 Blog / Changelog)
ベース checkpoint
Moonshot Kimi K2.5 + 合成 RL タスク 25x
価格 (per 1M tokens)
Standard $0.50 / $2.50, Fast $3.00 / $15.00
SWE-Bench Multilingual
79.8% (Opus 4.7 80.5% / GPT-5.5 77.8%)
「Cursor Composer 2.5 が出た。Opus 4.7 / GPT-5.5 と並ぶというが、自社製モデルが本当にフロンティアと張り合えるのか? Kimi K2.5 ベースで合成 RL タスクを 25 倍に拡張した、というアーキテクチャ上の意味は? そして価格は?」—— 本記事は Cursor 公式 Blog / Changelog / Forum を一次情報に、long-horizon コーディング agent モデルとしての Composer 2.5 を整理します。Sales Claw のように「数十回 tool call を連鎖させる」自律ループを実装している立場から、何が変わり、どこに罠があるかを書きます。
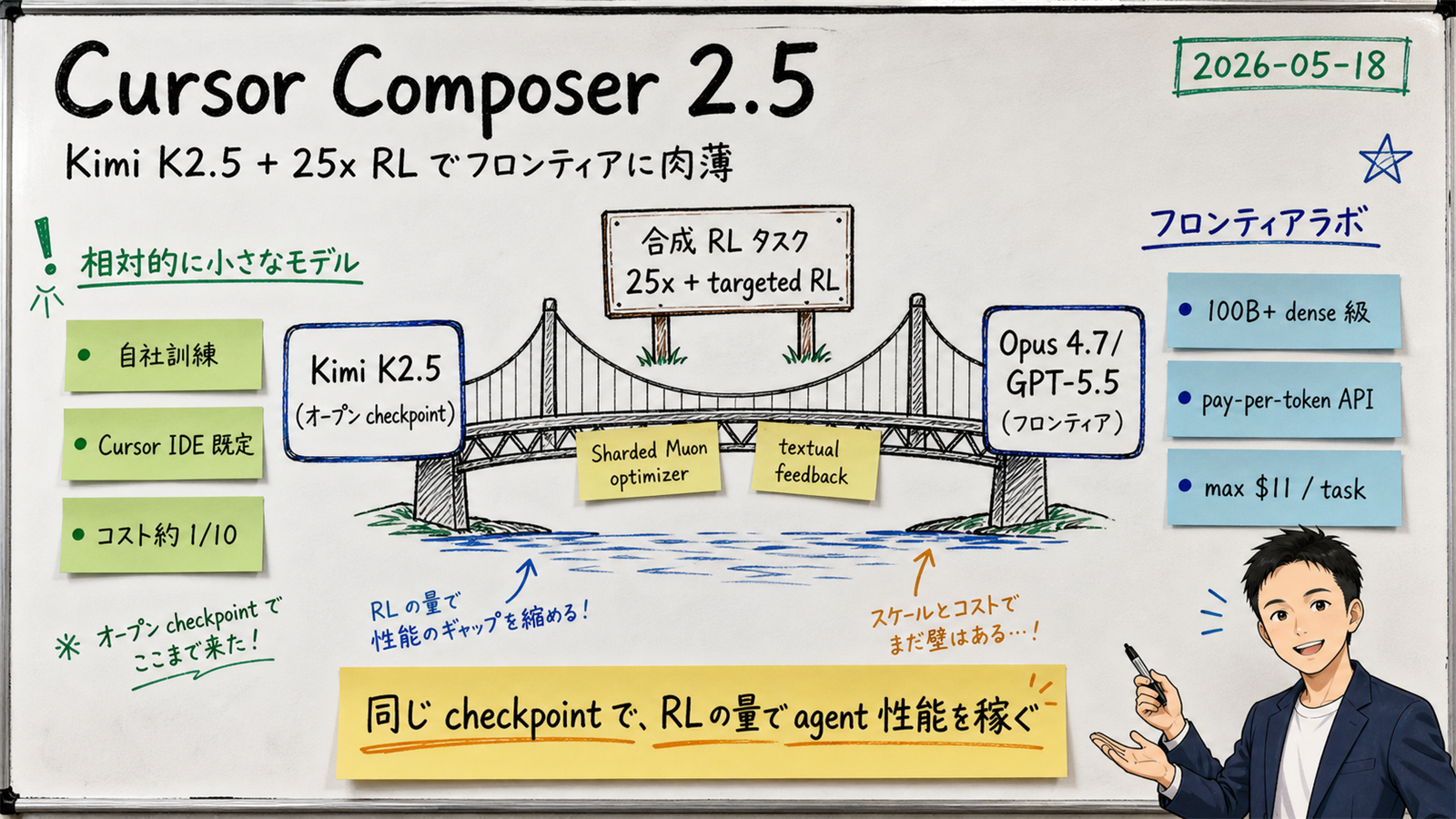
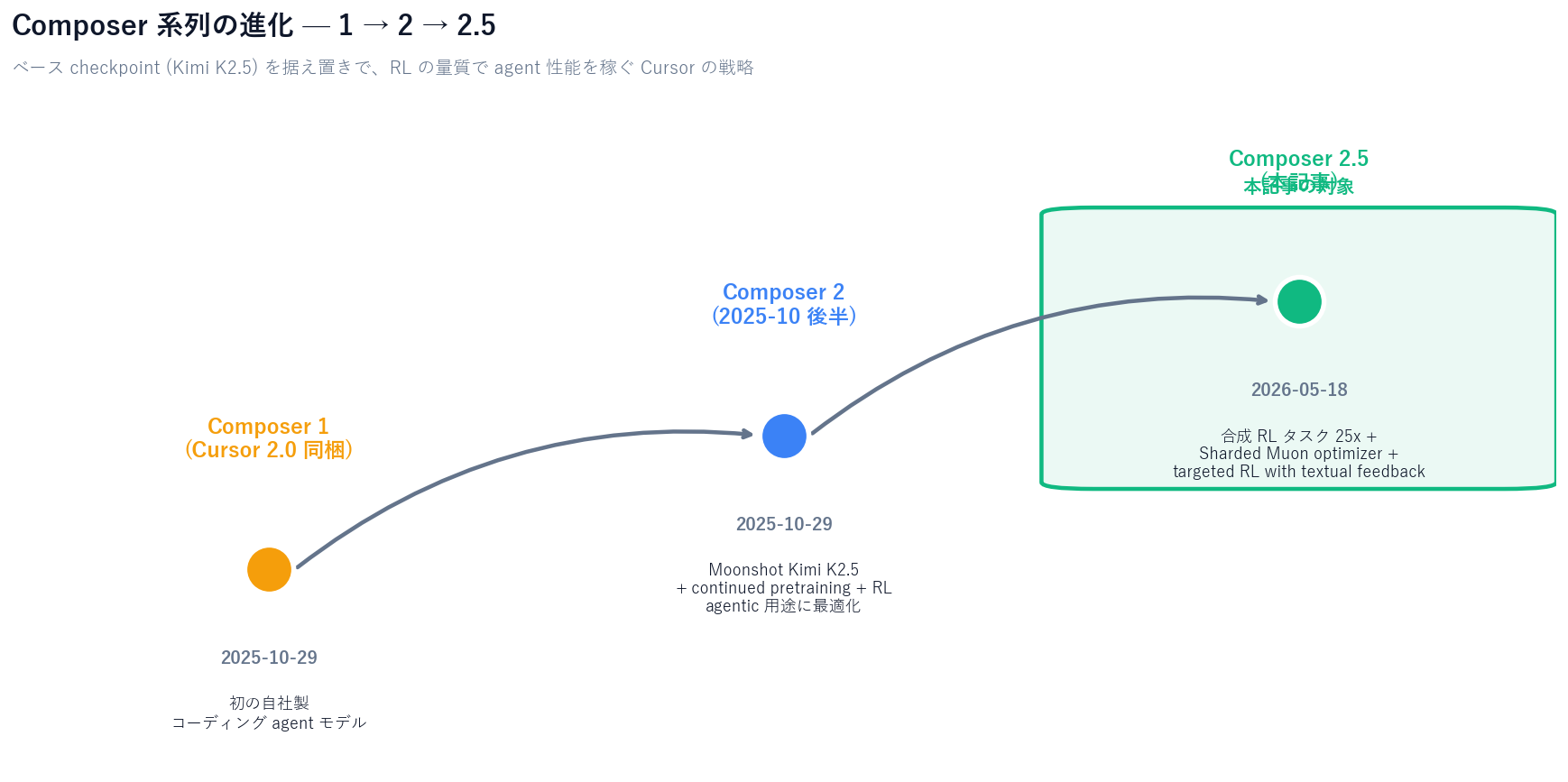
2026 年 5 月 18 日 (米国時間)、Cursor は自社製コーディングモデルの最新版 Composer 2.5 を公開しました。前モデル Composer 2 (2025-10 公開、Cursor 2.0 と同時) と同じく Moonshot Kimi K2.5 checkpoint を起点とした continued pretraining + RL ですが、合成 RL タスクの量を 25 倍に拡張し、Sharded Muon optimizer と distributed orthogonalization を投入してスケール耐性を確保しています。
本記事は Cursor 公式 Blog「Introducing Composer 2.5」(2026-05-18) / Cursor 公式 Changelog「Composer 2.5」/ Cursor Forum 公式アナウンス / Cursor 公式 Docs (Models) を一次情報として参照しています。社外ベンチや個別 X 投稿は本文の参考扱いに留め、JSON-LD citation には含めていません。
【公式発表】 Cursor 公式 Blog (2026-05-18) によれば、Composer 2.5 は 「our most powerful model yet」と位置づけられ、Composer 2 比で 「substantial improvement in intelligence and behavior」を達成したとされます。リリースと同時に Cursor アプリ内のデフォルトモデルとして切り替わり、Cloud Agents (バックグラウンド agent 実行基盤) でも採用されます。
【公式発表】 Composer 系の系譜は次の 3 世代です:
【著者見解】 系譜を見ると分かるのは、Cursor は「ベース checkpoint は据え置き、RL の質量で攻める」方針を取っていることです。前線フロンティアモデル (Opus 4.7 / GPT-5.5) を直接追いかけて weights をスクラッチから訓練するのではなく、Moonshot のオープン checkpoint を起点に「Cursor 上で本当に発生するタスク分布」へ RL で寄せる戦略。
【公式発表】 Cursor 公式 Blog および Changelog は、Composer 2.5 のベンチを 3 軸で公開しています。それぞれ Opus 4.7 / GPT-5.5 と相対比較した形になっており、第三者メディア (the-decoder, officechai) でも同じ数字が引用されています。
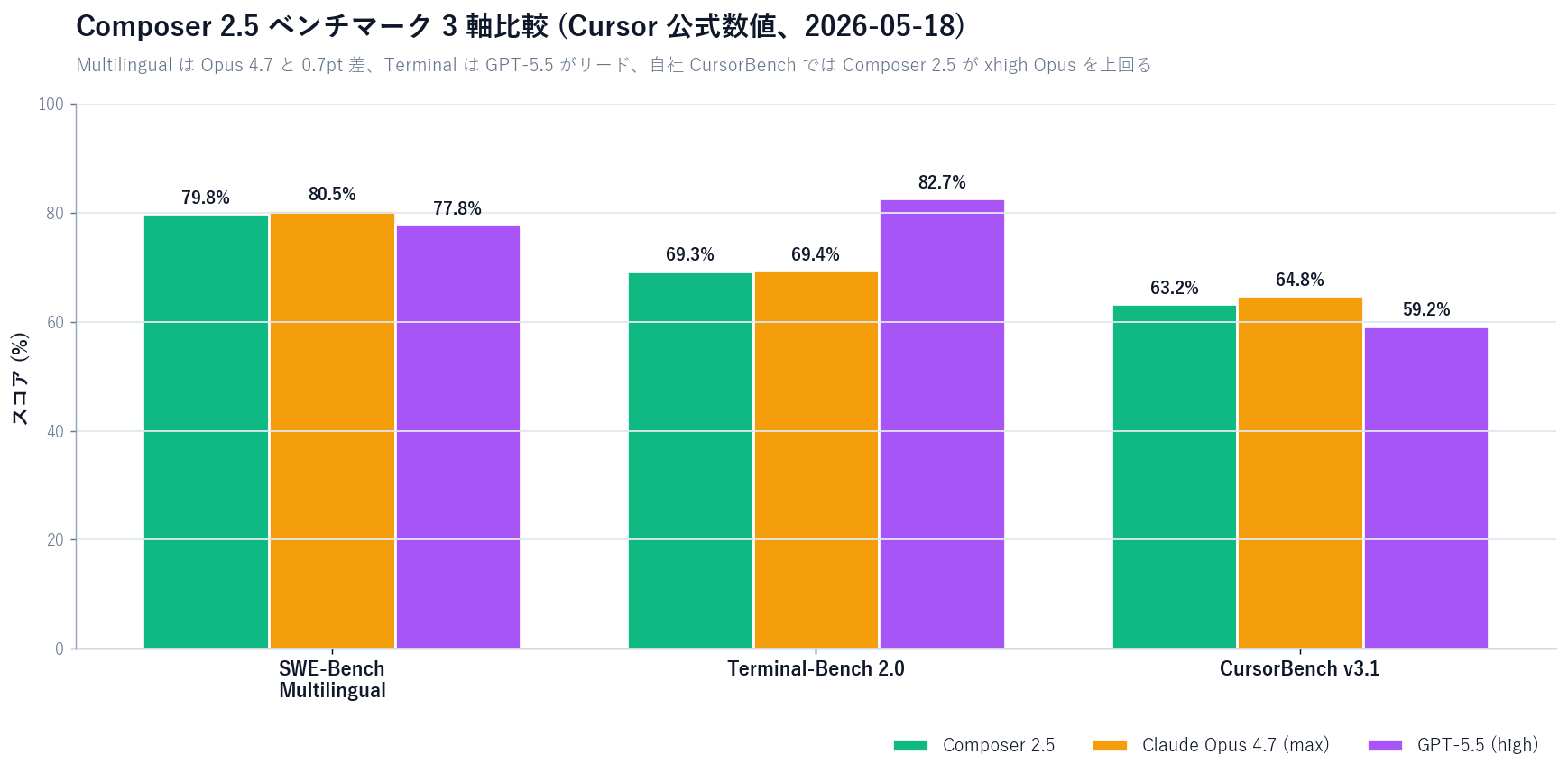
【公式発表】 SWE-Bench Multilingual (公式ベンチ、複数言語の実リポジトリパッチ生成) では Composer 2.5 が 79.8% を記録し、Opus 4.7 (80.5%) と 0.7pt 差、GPT-5.5 (77.8%) を 2pt 上回りました。Cursor 公式 Blog のチャートで明示されており、第三者メディアも同数字を引用しています。
【著者見解】 ここで意味があるのは「自社製の relatively small なモデルが、フロンティアラボの全力モデルと 1pt 以内に収まった」という事実そのもの。コーディング用途では「巨大汎用 LLM 一本足」ではなく「ドメイン特化 RL を厚く積んだ専門モデル」が現実的選択肢になったことを示します。
【公式発表】 Terminal-Bench 2.0 では Composer 2.5 が 69.3%、Opus 4.7 が 69.4%、GPT-5.5 が 82.7%で大きく抜けています。Terminal タスクは bash 操作・パッケージインストール・依存解決などを含む複合タスクで、GPT-5.5 の対 terminal 強化が反映されています。
【著者見解】 Terminal-Bench で差が付くのは「シェル系の細かいエラーメッセージ解釈・recover ロジック」。Cursor が IDE 内のエージェントタスクに最適化している分、ピュアな terminal リカバリでは GPT-5.5 が依然強いという解釈ができます。
【公式発表】 Cursor 内製の CursorBench v3.1 (実 Cursor 利用ログから合成したエージェントタスク群) では、Composer 2.5 が 63.2%。Opus 4.7 (max 64.8% / xhigh 61.6%) と GPT-5.5 (59.2%) と比べ、xhigh モードの Opus を上回り、max モードに 1.6pt 差で迫る成績です。
【著者見解】 自社ベンチは原理的に有利が出るので、ここを根拠に「Opus 4.7 超え」と断定するのは慎重にすべきです。CursorBench を引用するときは 「Cursor の利用パターンに特化したタスクで」という限定子を必ず付けて読むのが正しい姿勢。
| 項目 | Composer 2.5 (自社・relatively small) | Opus 4.7 / GPT-5.5 (フロンティア) |
|---|---|---|
| SWE-Bench Multilingual | 79.8% | Opus 80.5% / GPT-5.5 77.8% |
| Terminal-Bench 2.0 | 69.3% | Opus 69.4% / GPT-5.5 82.7% |
| CursorBench v3.1 | 63.2% | Opus max 64.8% / GPT-5.5 59.2% |
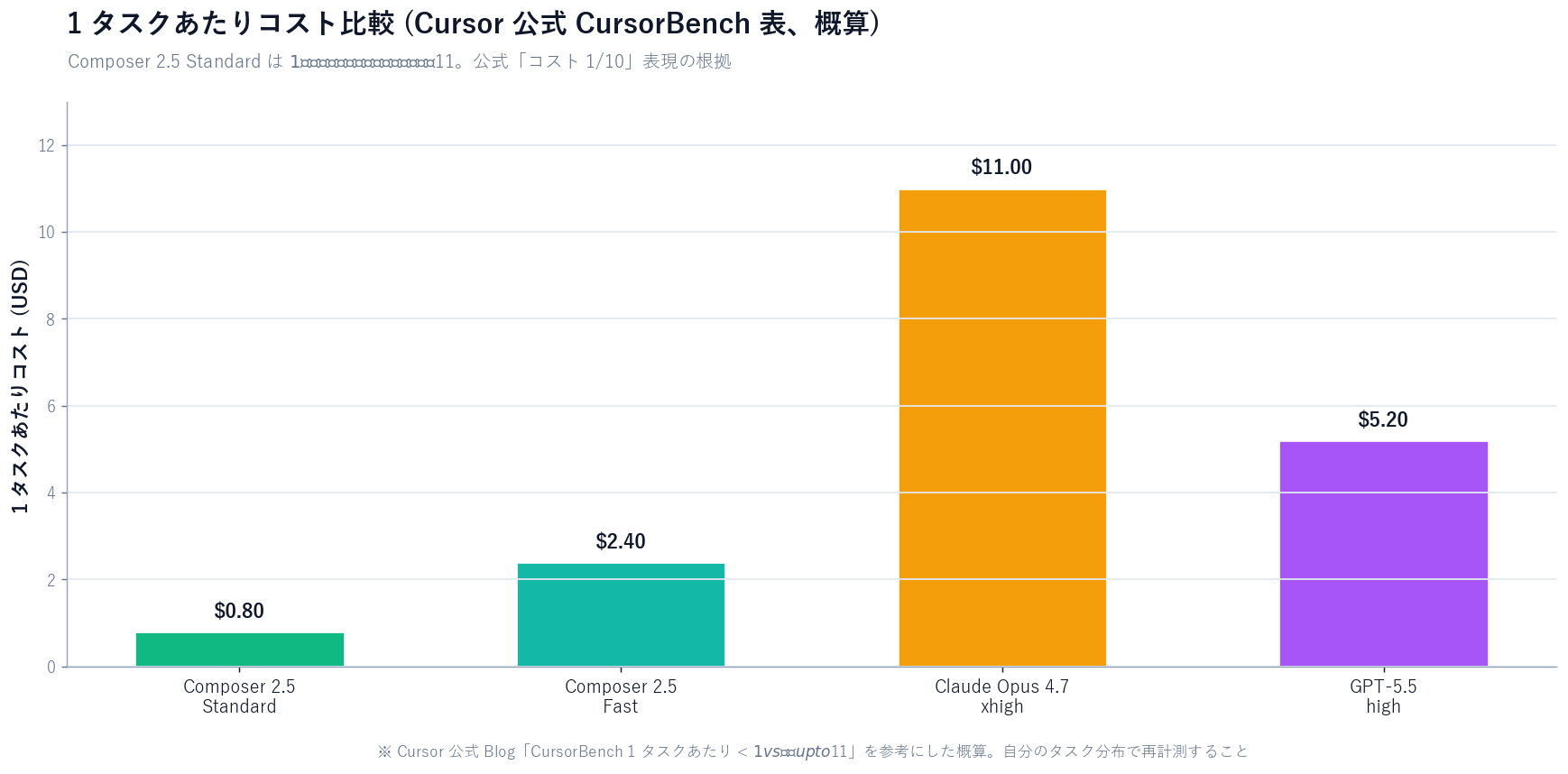
| 1 タスク当たりコスト (CursorBench, 公式表) | < $1 | 上位モデルは up to $11 |

【公式発表】 Cursor 公式 Blog はアーキテクチャ要素を 3 つ挙げています:
【著者見解】 この組み合わせから読み取れるのは「巨大 weights を持たずに、RL の品質と量で性能を稼ぐ」という戦略選択です。フロンティアラボのように 100B+ 級の dense モデルを抱える代わりに、 Kimi K2.5 (公開 MoE checkpoint) + 大量の合成エージェントタスク RL で「Cursor 上で本当に出現するタスク分布」に最適化する。これは Sales Claw のような業務特化エージェントが取りうる戦略と完全に同じ方向です。
【公式発表】 Composer 2.5 は Composer 2 比で合成 RL タスクの量が 25 倍に拡張されたと明記されています。具体的なタスク数の絶対値は公開されていませんが、Composer 2 の RL が「数万〜数十万タスク」だったと仮定すると、Composer 2.5 は百万オーダーに到達した計算になります(【推測】 公式絶対値なし)。
【公式発表】 Sharded Muon optimizer と distributed orthogonalization は、Muon optimizer (2024 年に Keller Jordan らが提案、SOAP 系の二次最適化) を多 GPU 環境でスケールするための工夫として導入されています。これは RL のスケールに伴う update 不安定性を抑えるための事実上必須の構成。
【公式発表】 Cursor は単純な数値報酬ではなく、textual feedback (自然言語フィードバック)を使って targeted な RL を回しています。具体的な手法詳細 (RLAIF 系か、Constitutional AI 系か) は公式で【未確認】ですが、特定の failure mode (たとえば「tool call ループを途中で止めてしまう」「複数ファイル編集で整合性を失う」) を狙って修正する設計と公式 Blog に書かれています。
【公式発表】 Cursor 公式 Blog は、Composer 2.5 が「sustained work on long-running tasks」で改善したと明記しています。具体的には「数百回の tool call を伴う long-horizon task で前モデルより成功率が高い」とされ、Cloud Agents で実用に耐えるサンプリング温度・温度別の安定性が向上したと述べています。
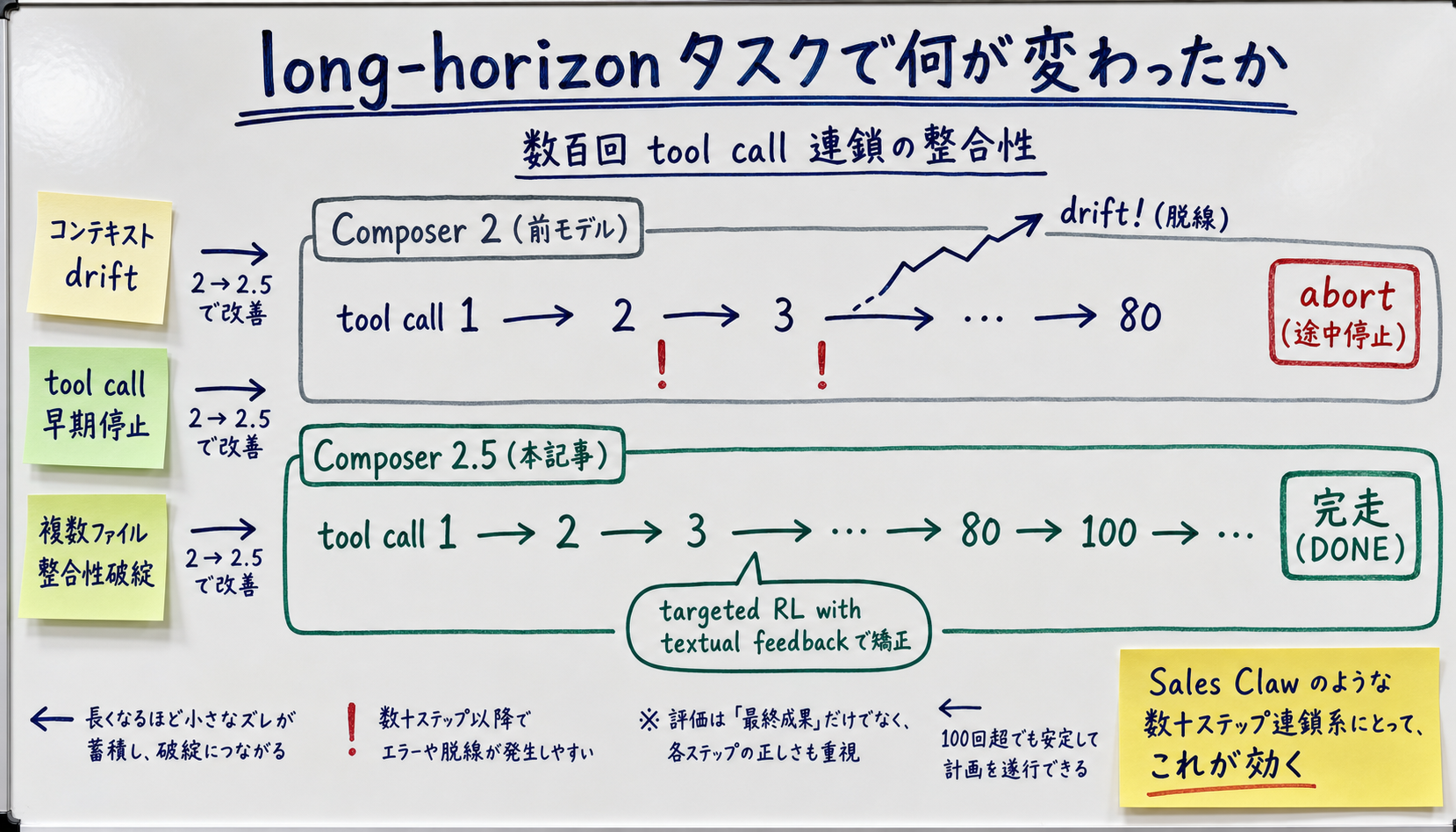
【著者見解】 実装観点で言えば、long-horizon agent の主要な失敗モードは次の 3 つ:
Composer 2.5 はとくに 2 番目 (早期停止) と 3 番目 (整合性) の改善に重点が置かれているように読めます。targeted RL with textual feedback の出口がここに使われているわけです。Sales Claw のように「企業調査 → フォーム解析 → 入力 → 検証 → 送信」の数十ステップを 1 ループにする系では、ここが効きます。
【未確認】 具体的に「何分まで耐久するか」「何回 tool call まで安定するか」は公式に明確な数値が出ていません。Cursor 公式 Blog の表現は「hundreds of tool calls」「sustained work」など定性的。実運用では Cloud Agents 側のタイムアウト (現状 60 分前後と推定、【推測】) と Composer 2.5 自体の文脈窓 (Kimi K2.5 が 200K-256K と公開されているのを継承していると推定、【推測】) のどちらが先に頭打ちするかを実測する必要があります。
【公式発表】 Cursor 公式 Changelog は Composer 2.5 の API ベース価格を以下のように公開しています:
【公式発表】 Cursor 公式 Blog はあわせて「CursorBench の 1 タスクあたりのコストが Composer 2.5 で < $1、競合フロンティアモデルでは up to $11」と主張しています。これが「コスト 1/10」の根拠表現で、絶対比は実タスク次第なので「事実」というより「自社ベンチでの中央値帯」として読むのが妥当です。
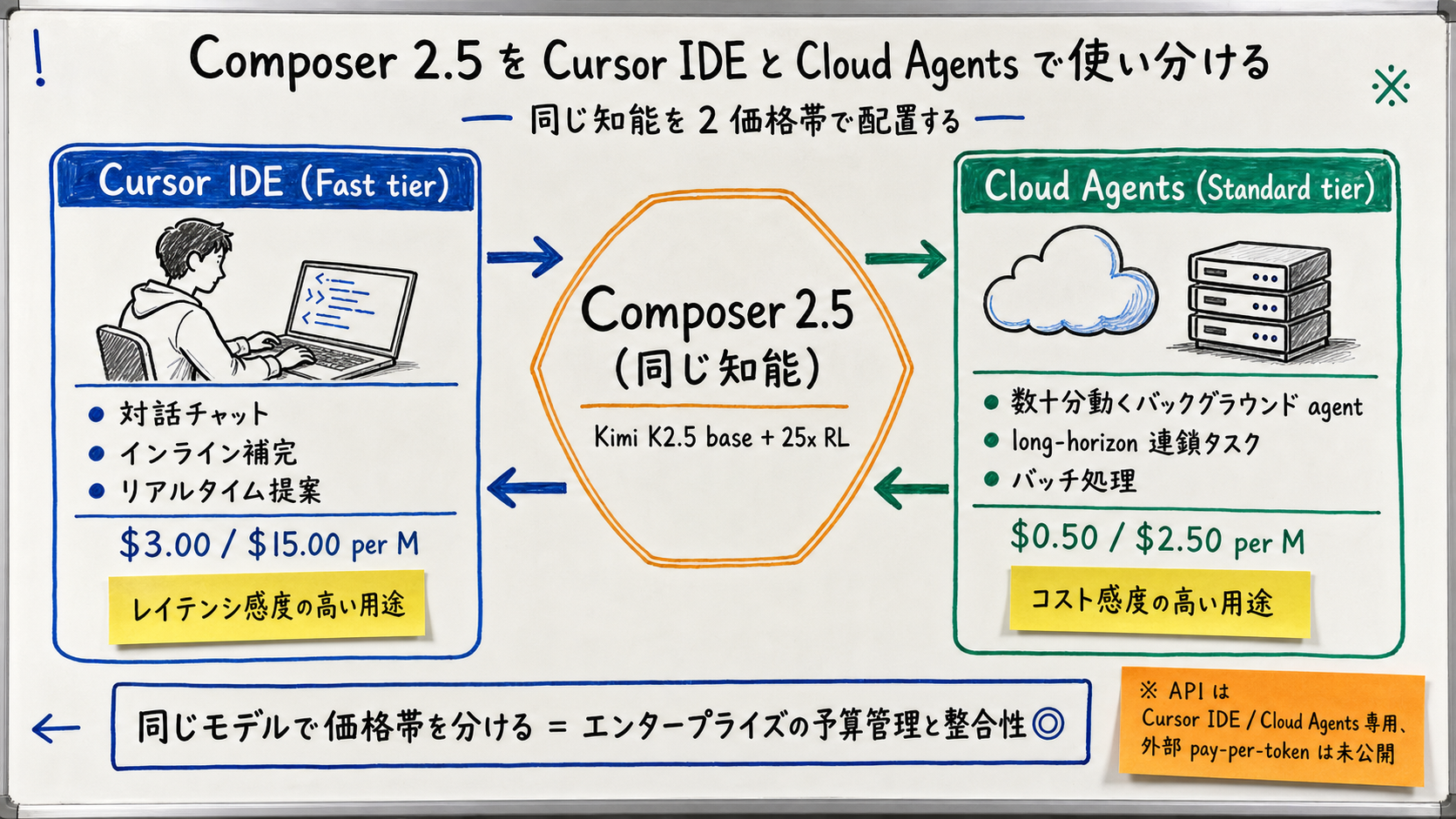
【著者見解】 Fast tier ($3.00 / $15.00) は「Standard と同じ知能をより高速に」提供する位置づけ。これは「Standard でレイテンシ的に遅い場面 (例: IDE 内のインライン提案・チャット返答)」を Fast に逃がす設計で、Cloud Agents のような後段 batch では Standard、IDE 対話では Fast、という運用が想定されます。 Anthropic / OpenAI が「同モデルで temperature / reasoning_effort を変えるダイヤル」を提供しているのに対し、Cursor は「同知能で 2 価格帯」という分け方を取っています。
【公式発表】 Pro / Business / Enterprise の含み枠 (included usage) が、リリースから 1 週間 (2026-05-18〜) は 2 倍に設定されます。【未確認】: 元の含み枠の絶対値はプランごとに異なり、公式 pricing ページの更新を待つ必要があります。 実運用では、この 1 週間で Composer 2.5 の体感を取り、コスト感を 2x boost なしの状態に補正して見積もるのが安全です。
【公式発表】 Cursor 公式 Changelog (Composer 2.5) によれば、利用には特別な設定は不要で、Cursor アプリの最新版で自動的に既定モデルが Composer 2.5 に切り替わります。明示固定するには:
【未確認】 2026-05-18 時点で、Composer 2.5 を Cursor IDE / Cloud Agents 外から直接 API 呼び出しする経路は公式に未公開。Anthropic / OpenAI のように pay-per-token で外部叩きする利用形態は提供されていません。 外部から組み込みたい場合は、現状 Cursor IDE の Cursor Agent / Background Agent 経由でラップする必要があります。API 公開計画の有無は公式 Docs および【公式発表】に注視する形になります。
【著者見解】 CursorBench v3.1 は「Cursor 利用ログを起点に合成されたタスク群」であり、Composer 2.5 がそこに RL で最適化されている以上、自社ベンチで上位に出ること自体は原理的に予測できる結果です。これを根拠に「Opus 4.7 を超えた」と語るのは過剰一般化のリスクがあります。 Multilingual SWE-Bench / Terminal-Bench 2.0 のような外部ベンチでの数字を主軸に判断するほうが安全です。
【未確認】 Composer 2.5 は Cursor IDE / Cloud Agents 専用で、Anthropic / OpenAI のような独立 API として提供されていません。Sales Claw のような自社プロダクトに直接組み込みたい場面では、現状以下の選択肢に絞られます:
【未確認】 Hacker News のスレッド (item?id=48182516) では、Composer 2 リリース時に「公式ベンチと実戦体感のギャップが大きい」という批判があり、2.5 でも一部再燃しています。これは個人の主観的体験ベースで opinionレベルの情報ですが、 「フロンティア比較は理想条件、実戦は別」という補正は常に意識すべきです。
【著者見解】 Sales Claw の現状アーキテクチャは「Claude Opus 4.7 / GPT-5.5 など外部 API モデルを LiteLLM 経由でルーティング、SDR 営業ワークフローを MCP (Model Context Protocol) で外部ツール連携し、送信前自動検査・営業 NG 検出・CAPTCHA 検出時停止・送信頻度制限・監査ログ保存 (action-log.json 形式) などのポリシー制御を上に被せて自律ループを構成、approachGuardrails で出力ガード、awaiting_approval で停止点保存」する設計です。webhook / OAuth で外部 SaaS と接続し、各記事の JSON-LD / canonical も自動生成しています。Cursor の Composer 2.5 戦略は、これを次の段階に進めるための示唆として読めます。
【著者見解】 BtoB 営業エージェント (Sales Claw を含む) の主な失敗モードは以下:
これらは「フロンティア LLM の知能を上げる」だけでは解決できず、 「業務固有の failure mode に対する targeted RL with textual feedback」 が必要な領域です。Composer 2.5 が示したのは、業務側がそのレシピを実装する道筋。Sales Claw の文脈で言えば、まずは MCP ツール連携と SDR 向けポリシー検査・送信前 NG 検出をルールベースで厚く積み、action-log.json と JSON-LD canonical 出力を整備し、運用ログから合成 RL タスクを蓄積して将来の特化モデル余地を残す、という設計が現実解です。LiteLLM ルーティングと OAuth / webhook 連携の薄膜越しに Composer 2.5 を加えるのも、近い将来の運用オプションです。
【著者見解】 Cursor の「Standard / Fast の 2 階層」は、Sales Claw のような営業エージェントにも応用できる考え方です:
同じモデルで価格帯を 2 階層に分けるという発想は、エンタープライズ運用の予算管理と整合性が良く、Sales Claw の料金設計でも採用余地があります。
【公式発表】 Cursor Composer 2.5 は 2026-05-18 リリース。Moonshot Kimi K2.5 ベースで合成 RL タスクを 25 倍に拡張し、SWE-Bench Multilingual で Opus 4.7 / GPT-5.5 と並ぶ性能を、約 1/10 のコストで提供する。Cursor IDE / Cloud Agents の既定モデルとして即時配信され、初週は included usage 2x。
【著者見解】 本リリースの本当の意味は「巨大 weights なしに、合成 RL の量質で agent 用途の実用品質に到達できる」路線が成立したことです。これは Sales Claw のような業務ドメイン特化エージェントが取りうる中長期の選択肢を 1 つ増やします。
【公式発表】 Cursor は次世代モデルを xAI Colossus 2 で 10x compute 規模で訓練中と発表しており、Composer 3 系列でフロンティア相当を狙う計画です。本記事の評価は 2026-05-18 時点のものとして読んでください。
本記事は X 公式アカウントと公式ドキュメントを一次情報として参照しています。