AIニュース
Claude Opus 4.8 Became an "Honest AI" — Benchmarks, New Features, and Cost, Explained for Non-Experts
15 分
Composer 2.5 (2026-05-18) takes the same Moonshot Kimi K2.5 checkpoint as Composer 2, scales synthetic RL tasks 25x, and lands on par with Claude Opus 4.7 / GPT-5.5 on SWE-Bench Multilingual at roughly 1/10 the cost. We pull from Cursor's official blog, changelog, and forum to cover benchmarks, architecture, pricing strategy, long-horizon improvements, the no-public-API risk, and Sales Claw's read on targeted RL.

中澤 圭志
@keishi_nakazawaSales Claw maintainer
Key Facts
Release date
2026-05-18 (US time, Cursor official blog / changelog)
Base checkpoint
Moonshot Kimi K2.5 + 25x synthetic RL tasks
Pricing (per 1M tokens)
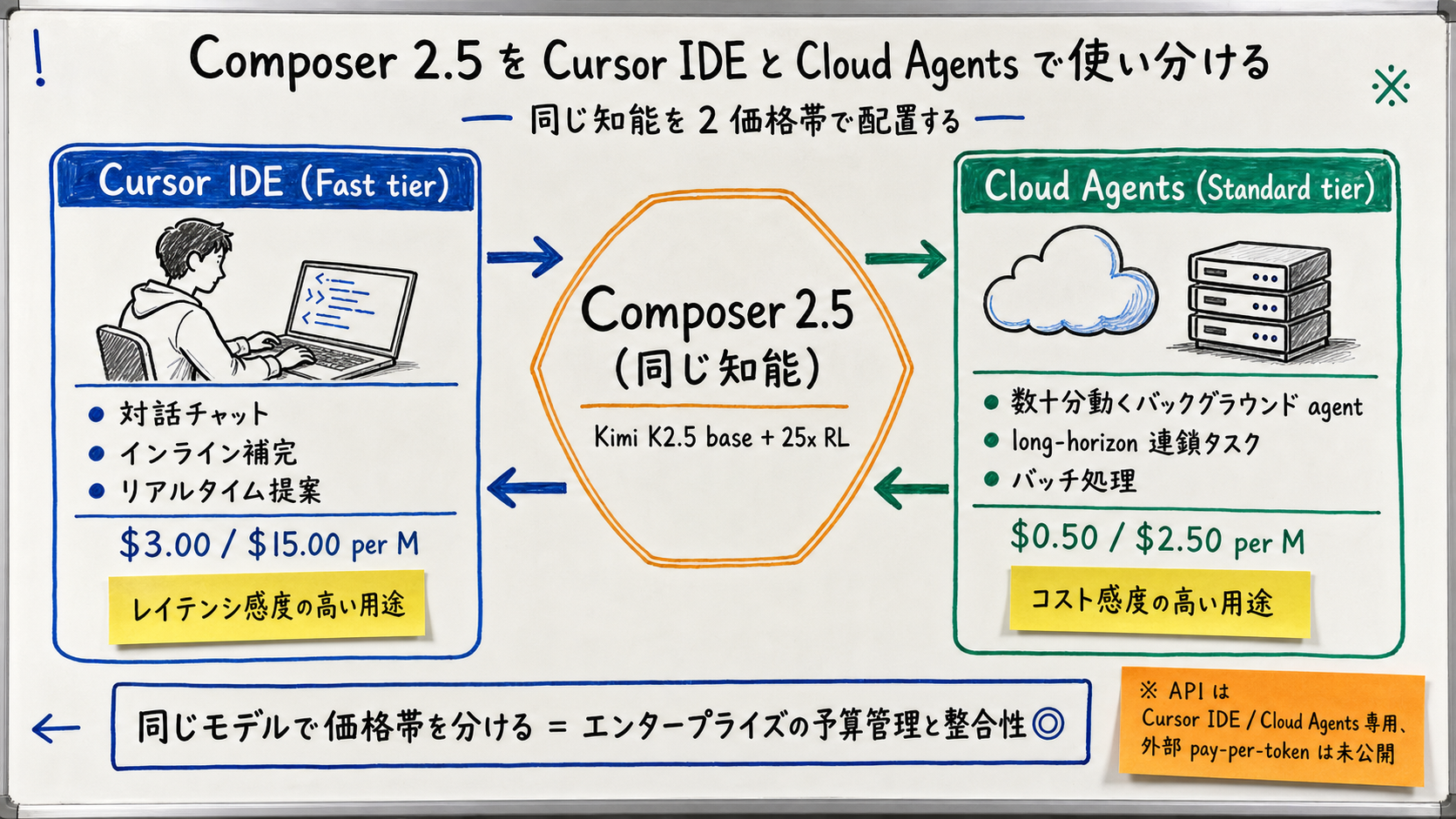
Standard $0.50 / $2.50, Fast $3.00 / $15.00
SWE-Bench Multilingual
79.8% (Opus 4.7 80.5% / GPT-5.5 77.8%)
"Cursor Composer 2.5 just shipped. The post says it lines up with Opus 4.7 and GPT-5.5, but can a vendor-built model really hold its own against the frontier? What does it mean architecturally to take the same Kimi K2.5 base and 25x the synthetic RL workload? And what about the pricing?"—— This article walks through Composer 2.5 as a long-horizon coding agent model, using Cursor's official blog, changelog, and forum as primary sources. We write from the seat of a team that builds self-running loops where dozens of tool calls chain together (Sales Claw), and we focus on what changed and where the traps are.
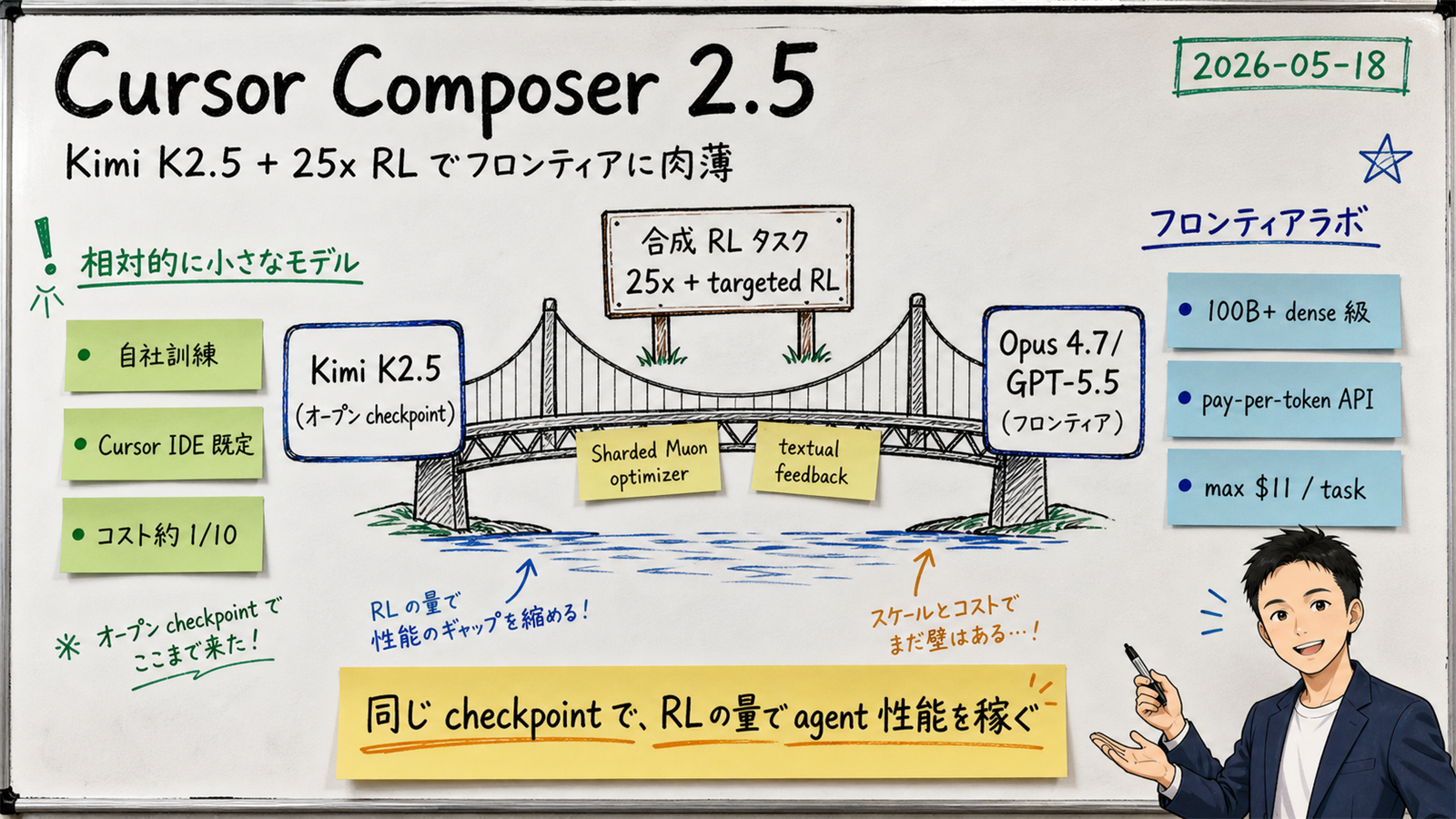
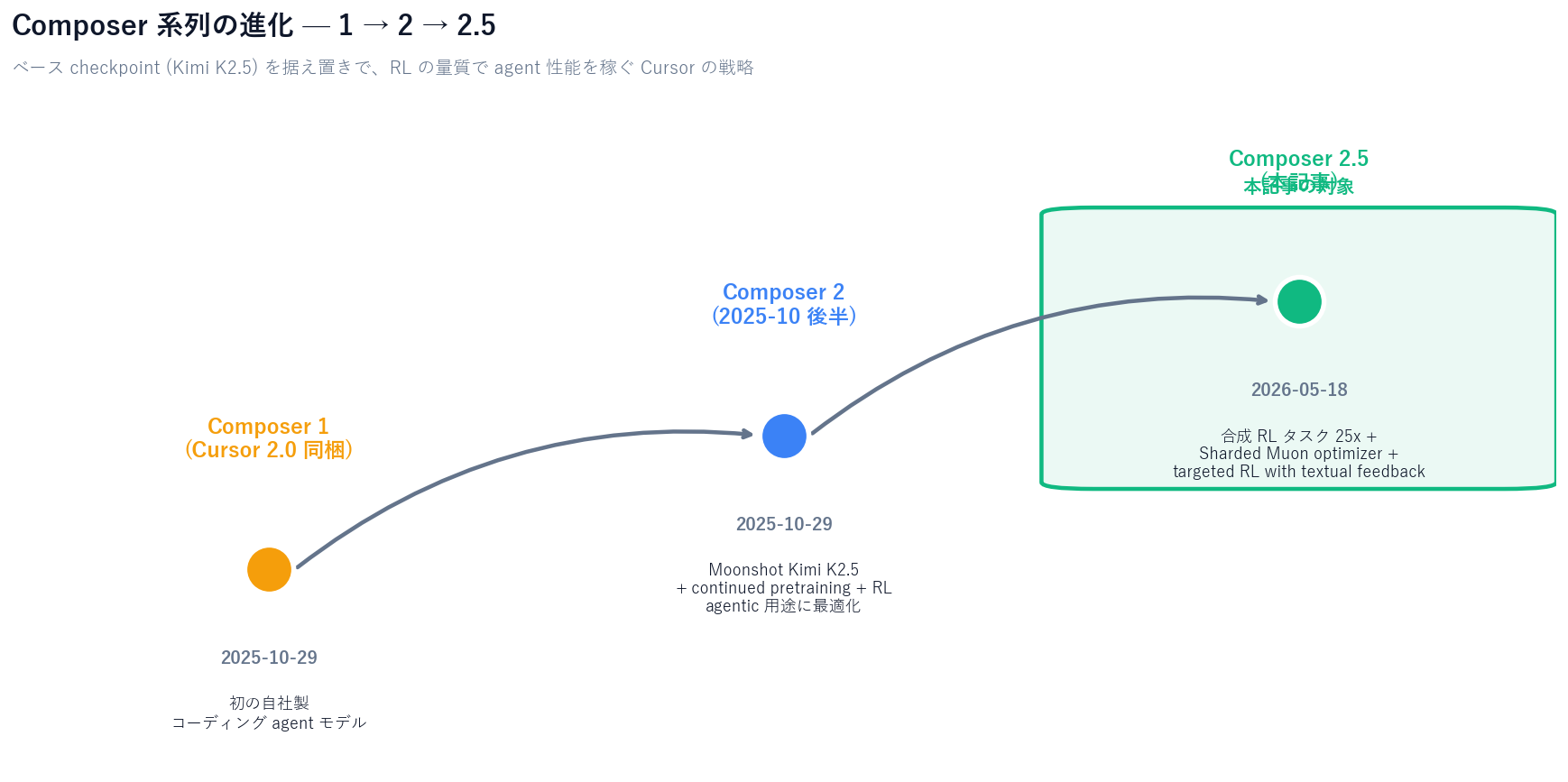
On May 18, 2026 (US time), Cursor released the latest revision of its in-house coding model, Composer 2.5. Like the previous Composer 2 (shipped 2025-10 alongside Cursor 2.0), Composer 2.5 starts from the Moonshot Kimi K2.5 checkpoint and adds continued pretraining plus RL on top — but the volume of synthetic RL tasks is now 25x larger, and the optimizer stack is upgraded to Sharded Muon with distributed orthogonalization to keep the RL run scalable.
This article uses the Cursor official blog ("Introducing Composer 2.5", 2026-05-18), the Cursor changelog (Composer 2.5), the official Cursor forum announcement, and the official Cursor docs (Models) as primary sources. Third-party benches and individual X posts are treated as auxiliary reading and are deliberately kept out of the JSON-LD citations.
[Official] The Cursor official blog (2026-05-18) frames Composer 2.5 as "our most powerful model yet", claiming a "substantial improvement in intelligence and behaviour" over Composer 2. At release, Composer 2.5 became the default model inside the Cursor app and is also adopted as the default in Cloud Agents (the background-agent execution platform).
[Official] The Composer lineage is three generations deep:
[Author's view] Read across the lineage and a clear strategy emerges: "hold the base checkpoint constant and attack via RL volume and quality."Cursor isn't chasing the frontier labs by training a 100B+ dense model from scratch — instead, it starts from an open Moonshot checkpoint and pushes the model toward the actual task distribution observed inside Cursor itself via RL.
[Official] Both the Cursor blog and changelog report Composer 2.5 benches on three axes, each compared against Opus 4.7 and GPT-5.5. Third-party outlets (the-decoder, officechai) cite the same numbers.
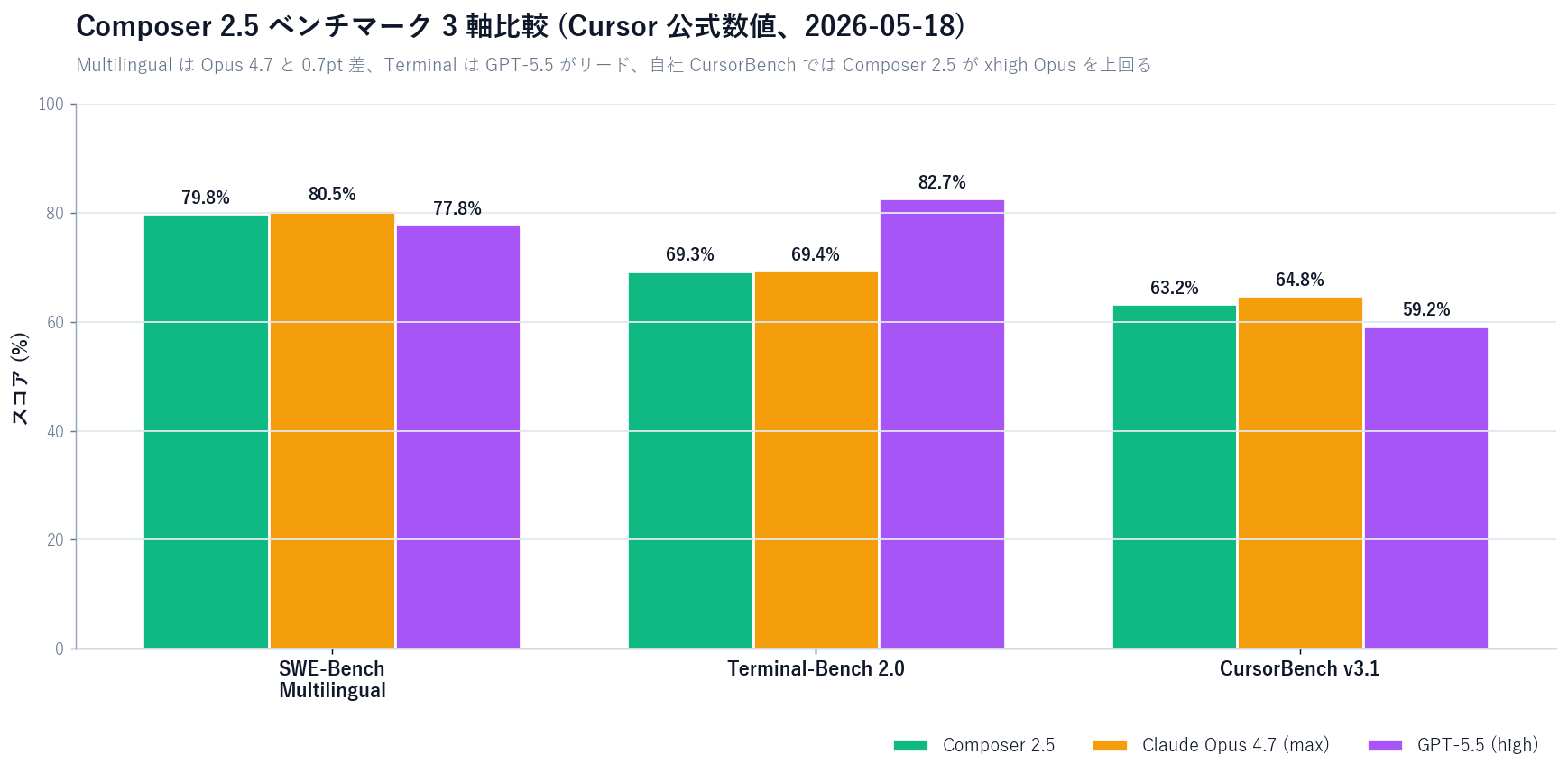
[Official] On SWE-Bench Multilingual (the official benchmark for cross-language real-repo patch generation), Composer 2.5 scores 79.8%, just 0.7pt below Opus 4.7 (80.5%) and 2pt above GPT-5.5 (77.8%). The chart is in the Cursor blog, and third-party outlets quote the same figures.
[Author's view] The meaningful fact here is simply that "a relatively small in-house model lands within one point of the frontier labs' full-power models." For coding workloads, the choice is no longer "giant general-purpose LLM only" — a thick layer of domain-specific RL on top of a specialised model is now a realistic option.
[Official] On Terminal-Bench 2.0, Composer 2.5 hits 69.3%, Opus 4.7 hits 69.4%, and GPT-5.5 pulls ahead at 82.7%. Terminal tasks here combine bash operations, package installs, and dependency resolution — areas where GPT-5.5's terminal reinforcement clearly shows.
[Author's view] The differentiator on Terminal-Bench is "reading subtle shell error messages and recovering from them." Cursor optimises Composer 2.5 for IDE-resident agent tasks, so it makes sense that GPT-5.5 is still ahead on pure terminal recovery loops.
[Official] On Cursor's in-house CursorBench v3.1 (synthetic agent tasks composed from real Cursor usage logs), Composer 2.5 scores 63.2%. That beats Opus 4.7 xhigh (61.6%) and lands within 1.6pt of Opus 4.7 max (64.8%). GPT-5.5 trails at 59.2%.
[Author's view] In-house benches are structurally biased toward in-house models, so claiming "we beat Opus 4.7" on the back of CursorBench is risky. When you cite CursorBench, always attach the qualifier "within the Cursor usage distribution."
| 項目 | Composer 2.5 (in-house, relatively small) | Opus 4.7 / GPT-5.5 (frontier) |
|---|---|---|
| SWE-Bench Multilingual | 79.8% | Opus 80.5% / GPT-5.5 77.8% |
| Terminal-Bench 2.0 | 69.3% | Opus 69.4% / GPT-5.5 82.7% |
| CursorBench v3.1 | 63.2% | Opus max 64.8% / GPT-5.5 59.2% |
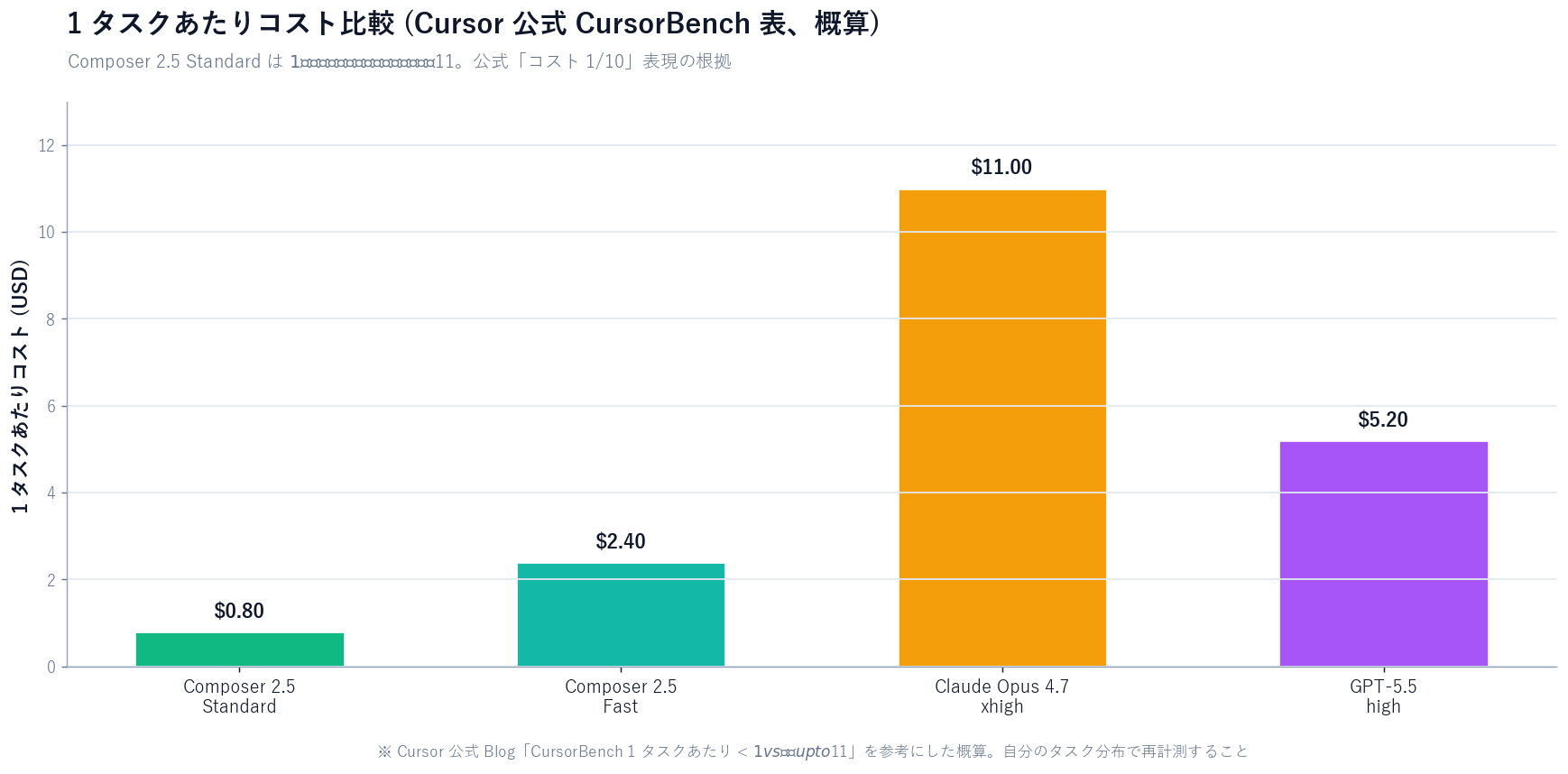
| Cost per task (CursorBench, official table) | < $1 | Frontier models up to $11 |

[Official] The Cursor blog lists three architectural ingredients:
[Author's view] What you can read out of this stack is a clear strategic choice: "earn capability through RL quality and quantity, not by carrying giant weights." Instead of a 100B+ dense frontier model, Cursor takes Kimi K2.5 (a public MoE checkpoint) and pumps in a huge volume of synthetic agentic-task RL to fit the "tasks that actually happen inside Cursor." This is exactly the direction a domain-specialised agent like Sales Claw could take.
[Official] Cursor is explicit that Composer 2.5 has 25x the volume of synthetic RL tasks compared to Composer 2. The absolute number is not disclosed, but if Composer 2's RL used tens to hundreds of thousands of tasks, Composer 2.5 is plausibly into the millions ([Speculation] — no official absolute is provided).
[Official] Sharded Muon optimizer with distributed orthogonalization is essentially the scaling toolkit for the Muon optimizer (proposed by Keller Jordan and others in 2024; a second-order optimizer related to SOAP). It addresses the update instability that becomes practically unavoidable when you scale RL this aggressively.
[Official] Rather than scalar reward alone, Cursor uses textual feedback (natural-language feedback) to drive targeted RL. The exact technique (RLAIF-style? Constitutional AI-style?) is not specified, so it remains [Unverified]— but the blog explicitly describes the design as "surgically" fixing specific failure modes (e.g. "abandoning a tool-call loop too early" or "losing consistency across multi-file edits").
[Official] The Cursor blog is explicit that Composer 2.5 improves on "sustained work on long-running tasks." Concretely, the success rate on long-horizon tasks involving hundreds of tool calls is now higher than the previous model, and sampling-temperature stability has improved enough to make Cloud Agents practical, per the post.
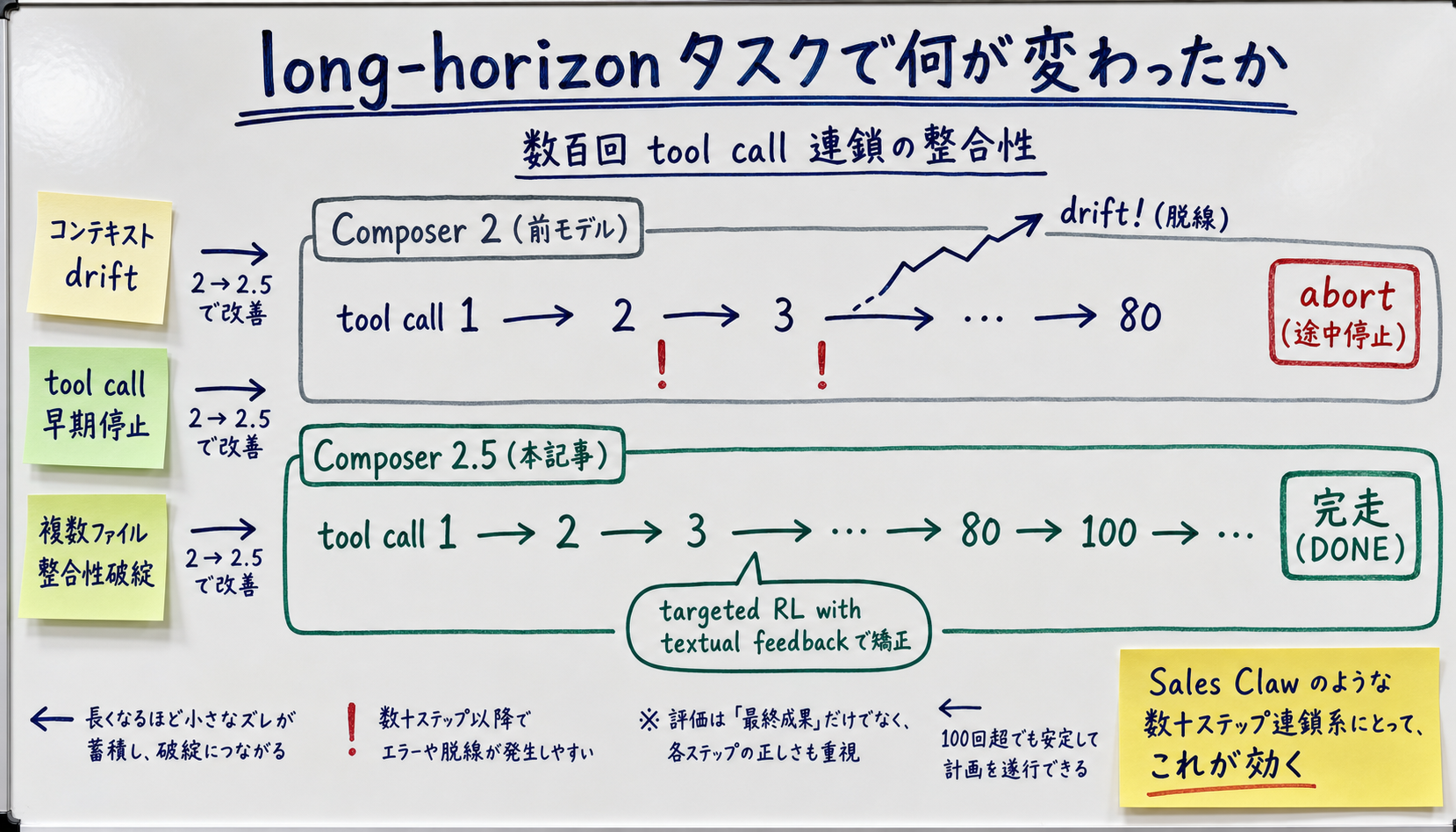
[Author's view] From an implementation standpoint, the three dominant failure modes for long-horizon agents are:
Composer 2.5 seems to put particular weight on fixing (2) and (3). This is where targeted RL with textual feedback finds its outlet. For products like Sales Claw — where one loop is "company lookup → form parsing → input → validation → send" spanning dozens of steps — this is exactly the improvement that matters.
[Unverified] Cursor doesn't publish hard numbers for "how many minutes / how many tool calls before instability sets in." The blog stays qualitative: "hundreds of tool calls," "sustained work," etc. In real deployments, you'll have to measure for yourself which ceiling hits first: the Cloud Agents timeout (estimated ~60 minutes, [Speculation]) or the Composer 2.5 context window (inherited from Kimi K2.5's published 200K–256K, [Speculation]).
[Official] Cursor's changelog publishes Composer 2.5's API price band as:
[Official] Alongside that, the blog asserts "CursorBench per-task cost is under $1 for Composer 2.5 vs up to $11 for competing frontier models."This is the source of the "1/10 cost" framing, but it's a median band on Cursor's own bench, not a universal fact — your tasks may land elsewhere.
[Author's view] The Fast tier ($3.00 / $15.00) is positioned to "deliver the same intelligence faster." The intent is to route latency-sensitive use cases (in-IDE inline suggestions, conversational chat) to Fast, while Cloud Agents (after-the-fact batch) stay on Standard. Anthropic and OpenAI offer dials like temperature and reasoning_effort on a single model; Cursor instead splits one model across two price tiers with identical intelligence.
[Official] Pro / Business / Enterprise included usage is doubled for the first week (2026-05-18 onward). [Unverified]: the absolute starting included usage isn't clearly published per plan on the pricing page, so you'll need to wait for the official update or read it from your management screen. In practice, use this first week to feel out Composer 2.5, then convert back to non-2x cost when estimating the steady-state bill.
[Official] Per the Cursor changelog (Composer 2.5), no special setup is required — the latest Cursor app automatically switches its default model to Composer 2.5. To pin it explicitly:
[Unverified] As of 2026-05-18, there is no published path to call Composer 2.5 directly outside of Cursor IDE / Cloud Agents. There is no equivalent of pay-per-token access via Anthropic or OpenAI APIs. If you need to embed it into another product, your current option is to wrap the Cursor Agent / Background Agent via webhook or CLI. Whether or not an open API is planned is something to watch in the official docs and [Official] announcements.
[Author's view] CursorBench v3.1 is "a synthetic task pool derived from Cursor usage logs," and Composer 2.5 has been targeted-RL'ed against it. It is structurally predictable that an in-house model leads on its own in-house bench. Citing this as "we beat Opus 4.7" is the kind of overgeneralisation that backfires later. Use external benches (SWE-Bench Multilingual / Terminal-Bench 2.0) as the primary basis for selection decisions.
[Unverified] Composer 2.5 is exclusive to Cursor IDE and Cloud Agents — there is no standalone API like Anthropic's or OpenAI's. If you want to embed it into your own product (the Sales Claw scenario), your options are limited to:
[Unverified] On Hacker News (item id 48182516), the thread carries a recurring criticism that "official Composer 2 benches diverge from real-world experience," and some of that has resurfaced for 2.5. This is opinion-grade information based on individual experience, but the broader correction — "frontier comparisons are ideal-condition results; production is its own thing" — is one you should always have on hand.
[Author's view] Sales Claw's current architecture calls external API models like Claude Opus 4.7 and GPT-5.5, wraps them with policy controls (pre-send automated inspection, sales-policy NG detection, halting on CAPTCHA, send-rate limits, audit logging), and runs a self-driving loop on top. Cursor's Composer 2.5 strategy reads like a guide to what the next step could look like.
[Author's view] The dominant failure modes for B2B sales agents (Sales Claw included) are:
None of these get solved purely by "making the frontier LLM smarter." They sit squarely in the territory where "targeted RL with textual feedback against business-specific failure modes" actually helps. What Composer 2.5 demonstrates is the recipe you would apply on the business side. For Sales Claw, the realistic sequence is: pile on rule-based policy inspection and pre-send NG detection in the short term, accumulate operational logs into synthetic RL tasks, and keep the door open for a future specialised model.
[Author's view] Cursor's "Standard / Fast two-tier" cost shape transfers cleanly to a sales agent like Sales Claw:
Splitting one model across two price tiers maps neatly onto enterprise budgeting, and the Sales Claw pricing model could adopt the same shape.
[Official] Cursor Composer 2.5 shipped 2026-05-18. Built on Moonshot Kimi K2.5 with a 25x scaled synthetic RL task pool, it lines up with Opus 4.7 and GPT-5.5 on SWE-Bench Multilingual at roughly 1/10 the cost. It is rolled out as the default model in the Cursor app and Cloud Agents, and the first week comes with 2x included usage.
[Author's view] The real significance of this release is that "a route to practical agent-grade quality without giant in-house weights" has become live. That expands the medium-term option set for business-specialised agents like Sales Claw by one full lane.
[Official] Cursor also announced it is training its next-generation model on xAI Colossus 2 at 10x the compute, aiming at frontier-tier with the Composer 3 line. Read the evaluation in this article as a snapshot of 2026-05-18.
This English version is a translation of the Japanese-language original. Where wording differs, the Japanese version governs.
本記事は X 公式アカウントと公式ドキュメントを一次情報として参照しています。
この記事の著者
中澤 圭志
Sales Claw maintainer
Designs and develops Sales Claw. Writes from the field on B2B sales automation and applied AI.