AIニュース
Claude Code v2.1.144 explained: /resume for background sessions, 75-second startup hang fixed, /usage-credits rename — what production users should know
12 分
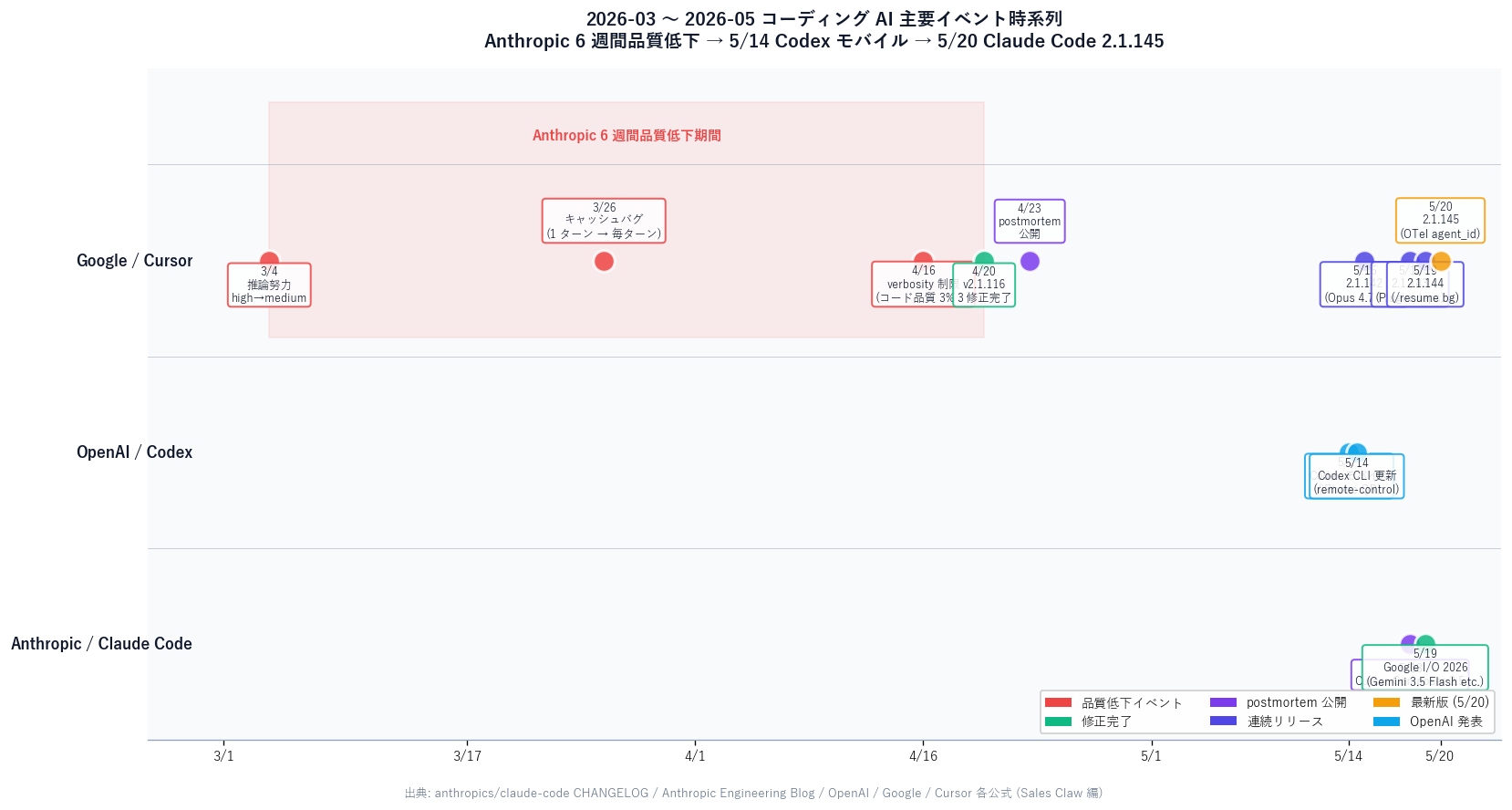
In the third week of May 2026, coding AI shipped three back-to-back "infrastructure era" events. Claude Code 2.1.145 (Fast mode defaults to Opus 4.7, OTel agent_id spans, 50+ improvements), OpenAI Codex mobile (iPhone QR-pair a Mac Codex session, 4M weekly users), and Anthropic publishing the technical detail of a six-week quality regression (three product changes — reasoning-effort downgrade / caching bug / verbosity limit — chained together). Read across three trends: tool → infrastructure, freedom from place and time, and SRE-grade quality accountability.

中澤 圭志
@keishi_nakazawaSales Claw maintainer

Key Facts
Claude Code latest
2.1.145 (2026-05-20, ~6 hours before publication)
Codex mobile
iPhone/Android preview (2026-05-14), QR-pair to Mac, 4M weekly users
Anthropic postmortem
v2.1.116 (2026-04-20) — all three product changes fixed
Common direction
Coding AI shifting from "tool" to "daily-use infrastructure"
TL;DR
In the third week of May 2026, the coding-AI industry shipped three back-to-back events that only happen once products enter "daily-use infrastructure". (1) Claude Code 2.1.145 landed six hours before this post — Fast mode silently switched to Opus 4.7 as default (introduced in 2.1.142), plugin dependency resolution went automatic, Windows right-click paste finally works, and 50+ other improvements shipped. (2) OpenAI Codex got remote control from iPhone / iPad / Android — pair your Mac with the ChatGPT app via QR code and drive a Codex session from anywhere. 4 million weekly active users. (3) Anthropic published the postmortem for a six-week stretch of Claude Code quality complaints, naming three overlapping product changes (reasoning-effort downgrade, caching bug, verbosity limit) and committing to a stricter rollout process. Fixed in v2.1.116. The thread that ties all three together is the same: coding AI is moving from "tool" to "daily-use infrastructure," and this post unpacks what that means for your own agent operations.
Bottom line: The third week of May 2026 was the week the coding-AI industry crossed from "tool" to "infrastructure" on three simultaneous fronts — feature surface, operating mode, and quality accountability. (1) The Claude Code 2.1.142 → 145 burst pushed Opus 4.7 into Fast mode, promoted background sessions to a first-class feature, and shipped OTel spans with agent_id / parent_agent_id so enterprise observability finally works. (2) Codex mobile dissolved the "I have to be at my terminal" assumption. (3) Anthropic's postmortem published the technical root cause of a six-week quality regression in detail. What ties them together is the weight of being used every day — the responsibility that comes with being infrastructure.
"Claude Code 2.1.145 dropped, Codex now runs on phones, Anthropic apologized for something — which one do I need to know about first?"— This post walks through the three coding-AI stories that landed between May 14 and May 20, 2026, using Anthropic's official engineering blog, the anthropics/claude-code GitHub Releases (CHANGELOG.md), OpenAI's official blog, and the OpenAI Codex changelog as primary sources. We then look at how each story should feed back into your own agent operations (Sales Claw included).
These three announcements look disconnected on the surface, but they share the same root: "running coding AI as daily infrastructure." Claude Code is doubling down on background sessions, plugin dependencies, and OTel to make daily operation viable; Codex is invading "non-terminal" time via remote control from phones; and Anthropic is taking on SRE-grade transparency for quality regressions. All three vendors are leaving the lab and moving into the infrastructure business — in the same week.
This article is structured as follows:
Primary sources for this post: Anthropic Engineering Blog (April 23 postmortem), anthropics/claude-code GitHub Releases (CHANGELOG.md), OpenAI's official blog (Work with Codex from anywhere), and the OpenAI Codex changelog. For the v2.1.144 release shipped one day earlier, see our Claude Code v2.1.144 walkthrough ; for cross-vendor comparisons that include Cursor Composer 2.5 and Antigravity 2.0, see our Google I/O 2026 roundup.
Timeline of what happened that week:
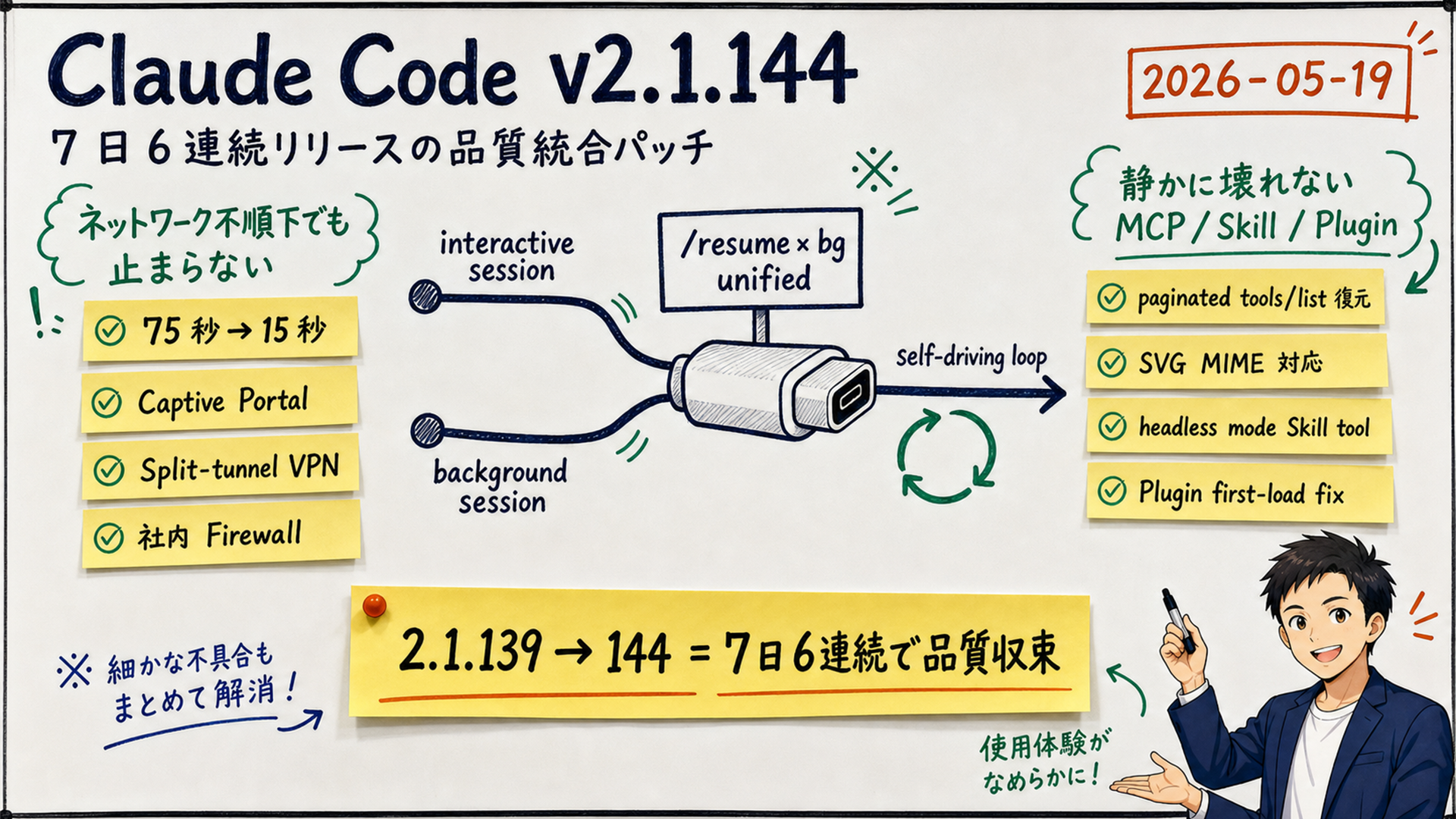
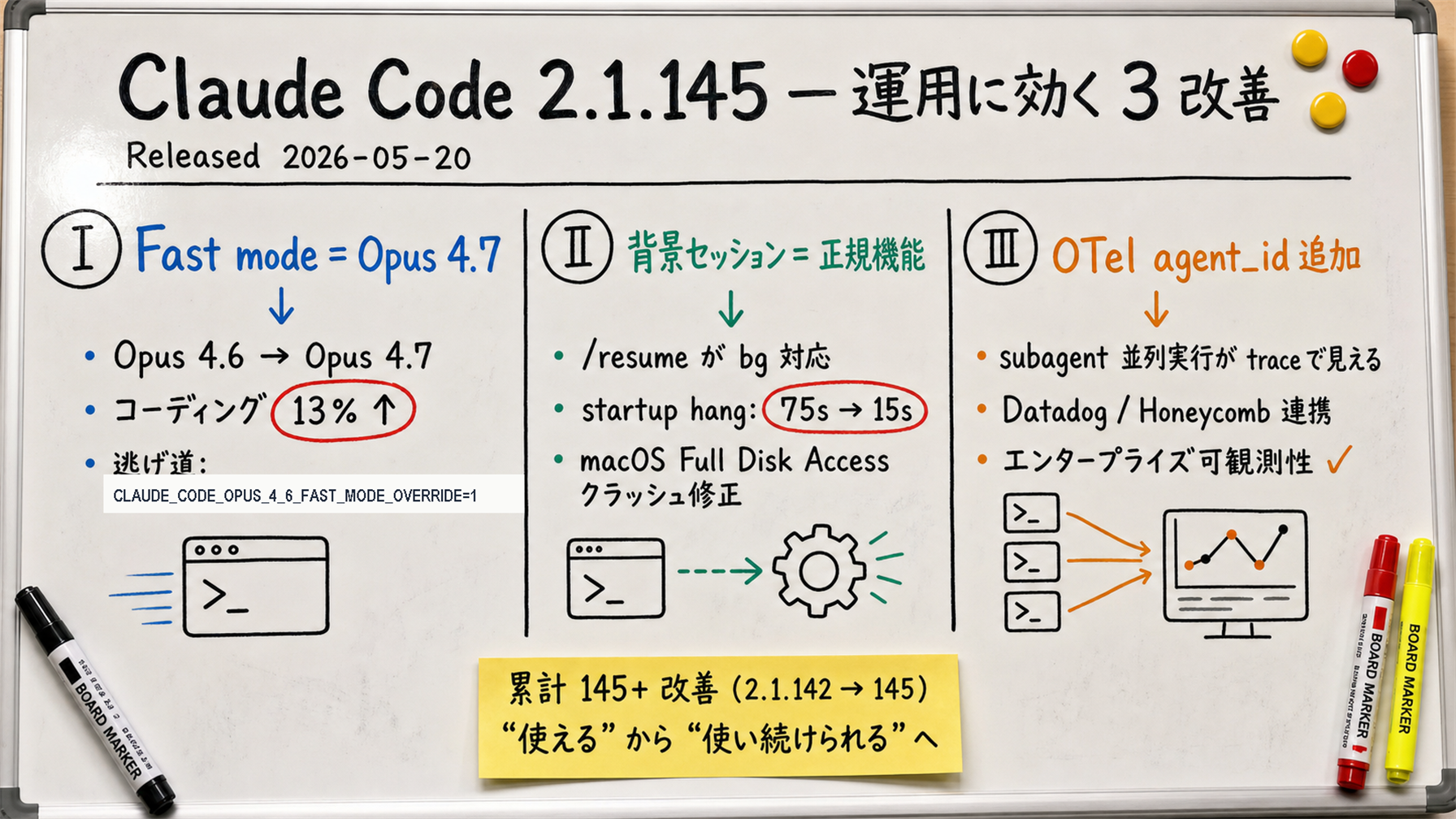
claude agents --json, OTel agent_id, permission-prompt bypass fix, and 50+ improvements.[Official] 2.1.142 switched Fast mode's default model from Opus 4.6 to Opus 4.7. Opus 4.7 is Anthropic's newest flagship, released on 2026-04-16, with a 13% lift on coding benchmarks over Opus 4.6. The "Fast mode" label and "speed first" positioning stayed identical — only the underlying model changed, silently.
[Author's view] The signal is that Anthropic now believes Opus 4.7's latency and unit economics are good enough to belong inside Fast mode. The accompanying CLAUDE_CODE_OPUS_4_6_FAST_MODE_OVERRIDE=1 escape hatch tells you they expect at least some users to want to roll back if they perceive quality regressions. For heavy uses inside Sales Claw — form-body generation, approachGuardrails judging — now is the time to re-benchmark under Opus 4.7.
[Official] 2.1.143 made background sessions preserve model and effort level after waking from idle; 2.1.144 added /resume support for background sessions, brought startup hang down from 75s to 15s, and fixed macOS Full Disk Access crashes.
Stacked together, these three fixes finally make "launch a task with claude --bg, let your Mac sleep overnight, /resume in the morning" actually work. Background sessions were labeled "experimental" before; with 2.1.144 they should be treated as a real, supported feature.
| 項目 | Before 2.1.142 (experimental) | From 2.1.144 (real feature) |
|---|---|---|
| Background session /resume | Not available, list unreliable | Resumable via /resume |
| Startup hang (when api.anthropic.com is unreachable) | 75s wait | 15s timeout |
| macOS Full Disk Access crash | Frequent under ~/Documents | Fixed |
| Model/effort preservation (after waking from idle) | Sometimes reset | Preserved |
| MCP pagination | First page only | All pages |
[Official] OpenTelemetry tracing spans now carry agent_id and parent_agent_id attributes. Until now, if you ran multiple subagents in parallel, you could not tell from the trace which call belonged to which subagent. With those two attributes you can reconstruct the parent-child relationship and visualize it in Datadog / Honeycomb / New Relic.
[Author's view] This is Anthropic's formal handshake with enterprise SRE teams running Claude Code. If you run a production agent like Sales Claw, this is a must-have: latency distributions for parallel subagent execution and per-agent token cost finally become visible inside Datadog APM.
[Official] claude agents --json now lists live Claude sessions as JSON — usable by tmux-resurrect, status bars, session pickers, and anything that wants to parse Claude state.
[Author's view] Anthropic is formally acknowledging the "Claude Code as scriptable component" use case. Until now you had to scrape ANSI-formatted TUI output. For Sales Claw-style autonomous operation, this opens a clean pipeline: "emit live subagent count to Slack or Datadog as a metric" is a five-minute job now.
[Official] 2.1.143: claude plugin disable now refuses when an enabled plugin depends on the target, and claude plugin enable force-enables transitive dependencies. 2.1.145: the /plugin Discover and Browse preview now shows a plugin's commands / agents / skills / hooks / MCP/LSP servers before installation.
[Author's view] The signal here is that the plugin ecosystem has matured to npm-level. With dependency resolution and pre-install metadata both in place, enterprise rollouts can show infosec exactly what a given plugin will add.
[Official] Right-click paste inside claude agents was broken on Windows Terminal and WSL; 2.1.143 fixes it.
[Author's view] For Windows-based Claude Code users, this is the moment "paste a git diff in, paste a log in" — daily mechanics that broke regularly before — finally works. Shift+Insert and Ctrl+V workarounds had been causing constant friction with CMD windows.
[Official] A permission-prompt bypass — "bare variable assignments to non-allowlisted environment variables in Bash commands were auto-approved" — has been fixed.
[Author's view] This is a security fix. Bash commands containing only a variable assignment (e.g., SECRET=$(cat .env)) were bypassing the permission prompt. For enterprise audit-log operation, that bypass was fatal. Sales Claw and similar agents should also audit whether internal secrets are being exposed through bash bridges.
[Official] Capabilities Codex mobile officially supports:
[Official] Files, credentials, permissions, and local setup stay on the Mac. The phone receives only "updates" — screen refreshes, terminal output, diffs, test results, and approval requests — in real time, end-to-end encrypted.
[Author's view] This is essentially the same model as Anthropic's Claude Code Remote Control (announced 2026-02), now applied to "my Mac → my phone" instead of "my Mac → my browser tab." It's designed to be compatible with enterprise data-exfiltration policies.
[Official] "Codex for Mac presents a QR code; scan it from iPhone / iPad / Android via the ChatGPT app". OpenAI's official blog has the step-by-step video.
[Author's view] QR pairing is "physical proximity required," which is enough security for this use case. Simpler than BLE pairing or OAuth, and compatible with the common enterprise pattern of "company Mac + personal phone."
[Official] At the same time, the Codex CLI gained: codex remote-control as a new entrypoint, Bedrock auth via AWS console-login credentials, paged thread views for app-server clients (unloaded / summary / full), multi-environment view_image, and the Python SDK migrating to openai-codex / openai_codex.
[Author's view] codex remote-control is described as "a simpler entrypoint for starting a headless, remotely controllable app-server." For OSS like Sales Claw that may want to "call a Hosted Codex under the hood," this is the reference implementation.
[Author's view] 2026 has been the year "coding AI × mobile" became a trend in earnest:
[Author's view] All four vendors are dismantling the assumption that "coding AI lives in a terminal." Sales Claw — built on a serverless autonomous loop — needs to align with this direction (for example, building a Slack / Email / mobile-app surface for approving Sales Claw sessions).
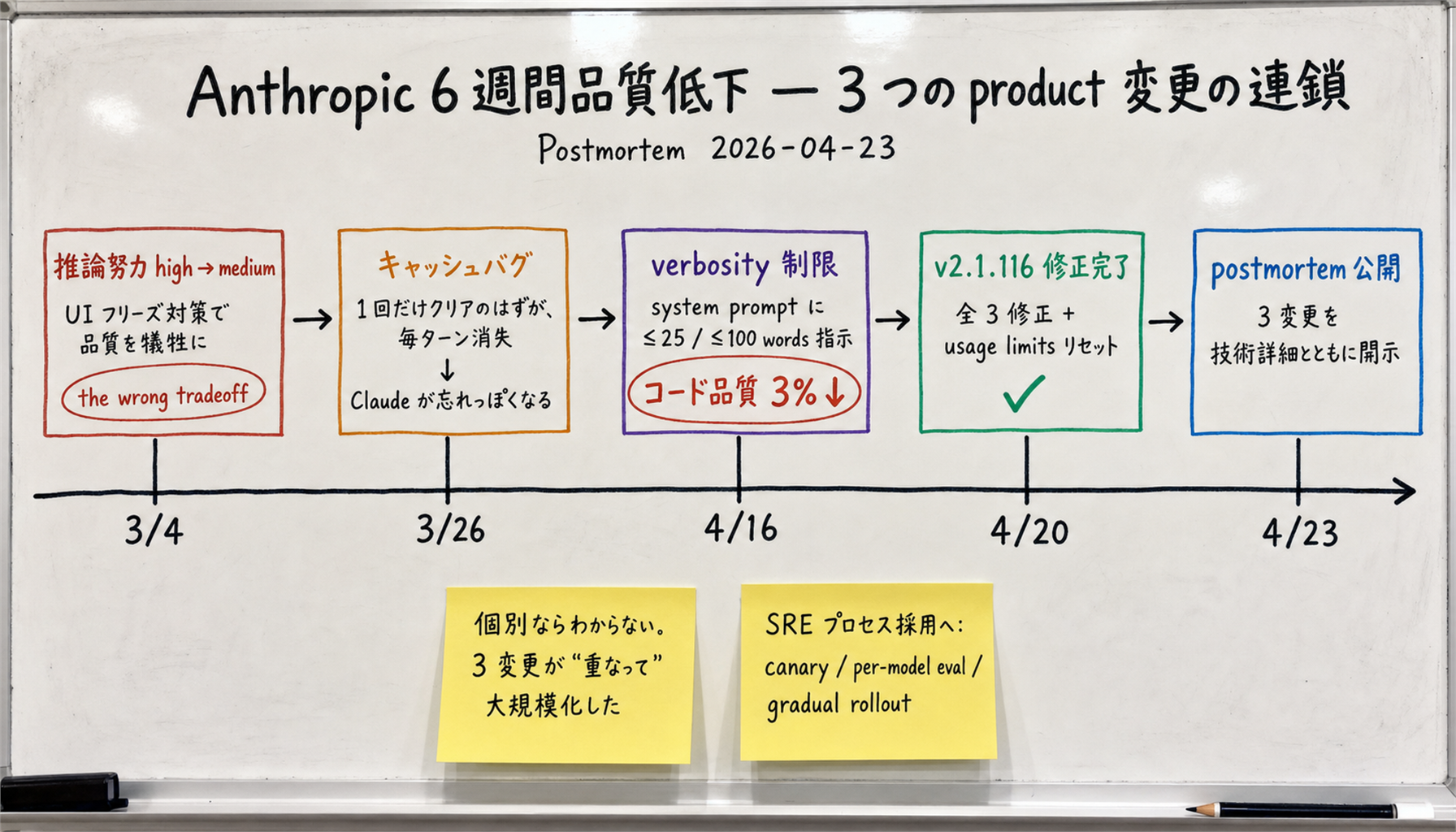
[Official] On 2026-03-04 Anthropic changed Claude Code's default reasoning effort from high to medium — to address "latency issues where the UI appeared frozen during long thinking periods."
| 項目 | Before 3/4 (high) | 3/4 → 4/7 (medium) |
|---|---|---|
| Default reasoning effort | high | medium |
| Perceived thinking time | Long, UI feels frozen | Short, snappy |
| Perceived code quality | High | Many users reported regression |
| Affected models | - | Sonnet 4.6 + Opus 4.6 |
[Official] Anthropic itself called this change "the wrong tradeoff". Reverted on 2026-04-07; the new default is now xhigh for Opus 4.7 and high for other models.
[Author's view] This is the classic "we mistraded latency for quality" lesson. Sales Claw and similar agents are exposed to the same trap. "Initial response is slow → reduce verbosity" looks like a quick win, but the perceived "quality dropped" reaction tends to be more damaging in practice.
[Official] On 2026-03-26 Anthropic shipped a change to "clear thinking history once for sessions idle 1+ hour" — to reduce resume latency. A logic error caused thinking history to be cleared on every turn for the rest of the session.
[Official] Impact: "Claude felt forgetful and repetitive" and "usage limits drained faster than expected." Affected Sonnet 4.6 + Opus 4.6. Fixed on 2026-04-10 in v2.1.101.
[Author's view] This is the classic "caching optimization with unintended side effects" pattern. "Run once" / "persist" branching logic is famously hard to unit-test and tends to surface only in production. Sales Claw's autonomous loop has equivalent exposure — for example, "save cookie on first try, reuse afterward" logic could mistakenly re-login every time.
[Official] On 2026-04-16 Anthropic added to the system prompt: "Keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail." Intent: cut the verbose output tokens of Opus 4.7.
[Official] Broader testing measured a 3% drop in code-generation quality across Opus 4.6 / 4.7. Affected Sonnet 4.6 + Opus 4.6 + Opus 4.7. Reverted on 2026-04-20.
[Author's view] This is the lesson that "a single line in the system prompt has unexpectedly wide blast radius." The intent was just to shorten verbosity, but it leaked into the reasoning expression used between tool calls and ended up degrading code generation. Sales Claw-style autonomous loops carry the same risk: "make form bodies more concise" could end up reducing the granularity of the approachGuardrails judge.
[Official] Anthropic committed to the following process improvements:
[Author's view] These are standard SRE practice. Anthropic publicly committing to "run Claude Code with SRE process" is the headline. Sales Claw and similar OSS agents in production should adopt the same.
[Author's view] Looking at the 50+ new features and 145+ bug fixes across Claude Code 2.1.142 → 145, more than half of the new features are about "making existing features durable." Examples:
These are infrastructure-grade requirements: "used every day," "never stops at night," "observed by SRE," "approved by infosec." The industry has moved from the 2024 era of "wow, it works" to the 2026 era of "zero downtime."
[Author's view] Codex mobile, Claude Code background sessions, and Antigravity standalone desktop — all three vendors are dismantling the assumption that "coding happens while you sit at a terminal."
This is the new model of "dispatch to coding AI, come back later to see the result." Sales Claw, in the long run, needs to align with this direction.
[Author's view] Anthropic publishing its postmortem is the symbolic moment of "coding-AI vendors adopting SRE process." Until now, AI quality regression was discussed only via user perception. Anthropic broke that pattern by:
These are baseline SRE / Cloud-SLA practices, but the AI industry has been able to skip them under the excuse that "we cannot explain what the model is doing." With this move, Anthropic has raised the bar for accountability across the industry.
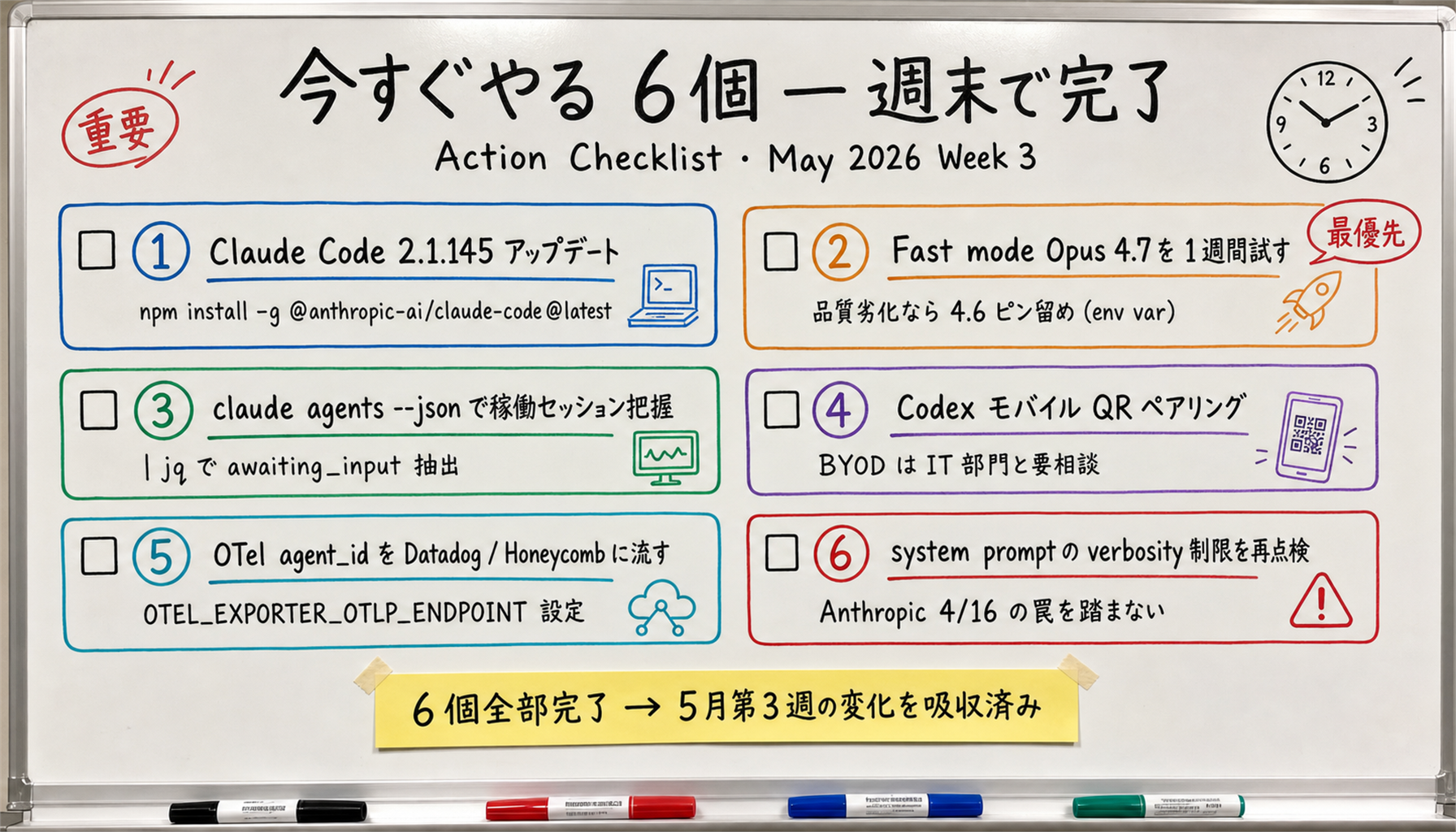
[Official] Claude Code is distributed via the @anthropic-ai/claude-code npm package. Check, then upgrade:
# Check current version claude --version # Upgrade to latest npm install -g @anthropic-ai/claude-code@latest # Re-check claude --version # → 2.1.145 (or newer patch)
[Author's view] If you are jumping from 2.1.142 or earlier, back up ~/.claude/.credentials.json before upgrading. 2.1.143 added a fix for "non-array scopes value in .credentials.json hangs the CLI on startup." If your old credentials are still there, re-login is safer.
With Fast mode now defaulting to Opus 4.7, watch for "is quality lower?" or "is cost higher?" over a week.
# Check current model setting claude /model # Verify Fast mode (Shift+Tab to cycle permission modes, then F to enter Fast mode) # Run 5-10 tasks in Fast mode # Pin to Opus 4.6 if you observe quality regression # Mac/Linux export CLAUDE_CODE_OPUS_4_6_FAST_MODE_OVERRIDE=1 # Windows PowerShell $env:CLAUDE_CODE_OPUS_4_6_FAST_MODE_OVERRIDE = "1"
# Dump all background sessions as JSON claude agents --json # Use jq to extract "awaiting-input" sessions only (Sales Claw operation example) claude agents --json | jq '.[] | select(.status == "awaiting_input")' # Call from a tmux status bar (~/.tmux.conf) # set -g status-right "#(claude agents --json | jq 'length') agents"
[Author's view] This is step one of "SRE-monitor Claude Code." In Sales Claw operation you can build "alert Slack when more than N sessions are awaiting input" in five minutes.
codex command)[Author's view] If you operate under a BYOD policy, check with IT before pairing. Files stay on the Mac, but screen updates and diffs do transfer to the phone.
[Official] Claude Code exports OTel via the OTEL_EXPORTER_OTLP_ENDPOINT environment variable:
# Stream to Datadog Agent export OTEL_EXPORTER_OTLP_ENDPOINT="http://localhost:4318" export OTEL_EXPORTER_OTLP_HEADERS="dd-api-key=<YOUR_API_KEY>" export OTEL_SERVICE_NAME="claude-code-sales-claw" # Stream to Honeycomb export OTEL_EXPORTER_OTLP_ENDPOINT="https://api.honeycomb.io" export OTEL_EXPORTER_OTLP_HEADERS="x-honeycomb-team=<YOUR_API_KEY>" # Start Claude Code — claude_code.tool spans now export with agent_id / parent_agent_id claude --bg "Run all tests for the project and summarize the results"
Filtering by service:claude-code-sales-claw in the Datadog APM dashboard now shows parallel subagent traces split out by agent_id.
[Author's view] In light of Anthropic's postmortem, grep your own system prompts and CLAUDE.md files for "be concise"-type instructions. For Sales Claw operation:
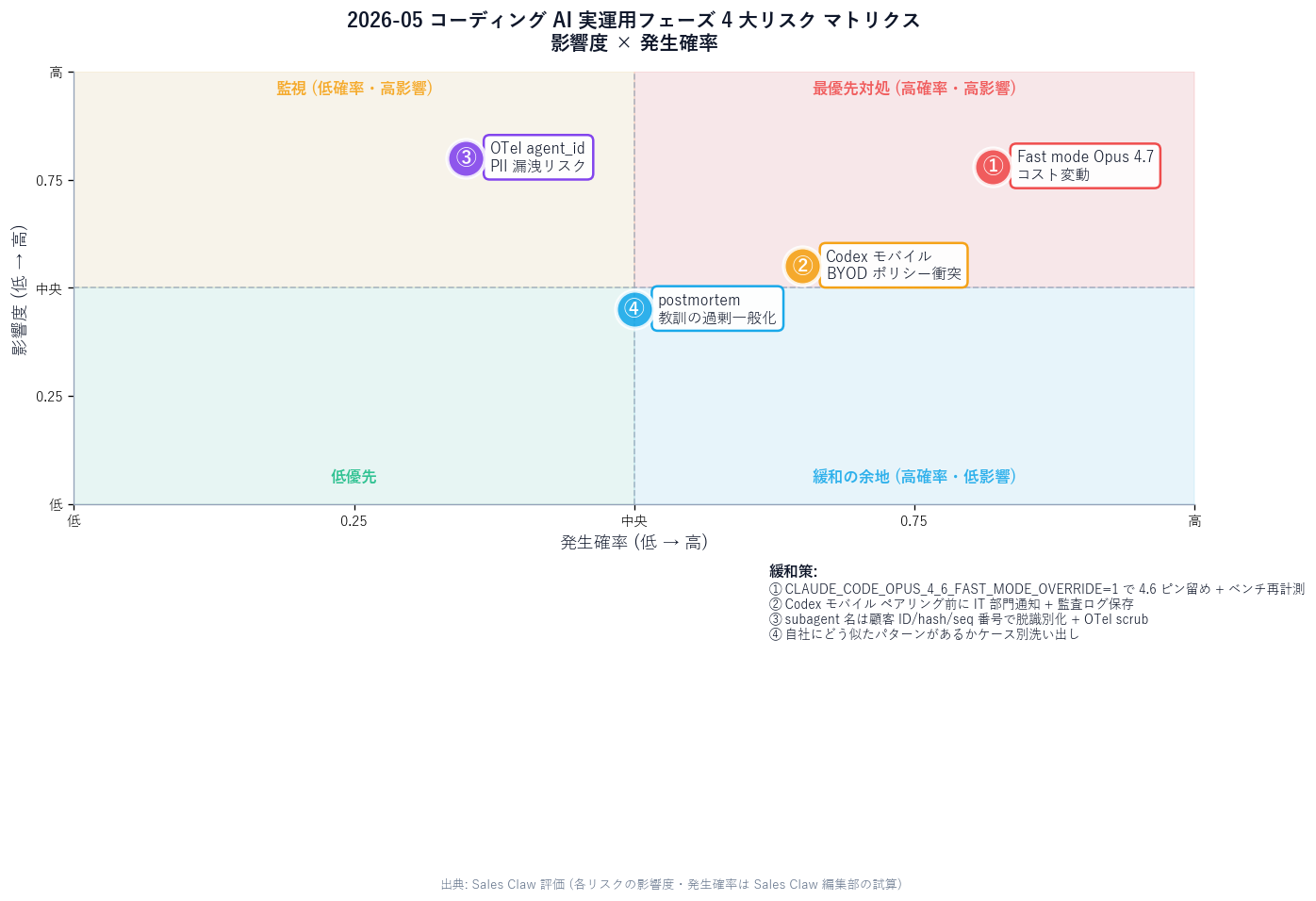
[Author's view] With Fast mode now defaulting to Opus 4.7, heavy Fast-mode users may see "unexpected monthly cost increases." Opus 4.7 is 13% better on coding benchmarks than Opus 4.6, but per-token price is "flat or slightly higher" in many cases. If you have pipelines that hit Fast mode frequently in Sales Claw operation, pull a cost report this weekend and compare before/after.
Mitigation: pin Fast mode to Opus 4.6 with CLAUDE_CODE_OPUS_4_6_FAST_MODE_OVERRIDE=1 and re-benchmark cost vs. quality on your own workload.
[Author's view] Codex mobile keeps "files and credentials on the Mac," but screen updates and diffs do transfer to the phone. Under a BYOD policy this means "some of your business code is now displayed on a personal phone" — and that usually requires IT approval.
Mitigation: company-issued iPhone removes the BYOD problem. Under personal-only policies, "notify IT before pairing and log pairing history in audit" is the safer pattern.
[Author's view] Claude Code 2.1.145 added agent_id and parent_agent_id to OTel spans — but if your subagent names contain customer names, those names now flow into Datadog / Honeycomb / external OTel collectors. Example for Sales Claw: --agent customer-acme-form-runner ends up looking like PII leakage in observability.
Mitigation: use de-identified values for subagent names ("customer ID," "customer hash," "sequence number"). Scrub attributes at the OTel collector via resource processors.
[Author's view] Anthropic's three cases are Claude Code-specific. They do not translate one-to-one to your own production agent. In particular, "verbosity limit lowered code quality" is a phenomenon tied to Claude Code's specific system-prompt structure; Sales Claw has an independent approachGuardrails judge model, so the dynamics differ.
Mitigation: read the postmortem and map "what similar patterns exist in our system" case by case (do not swallow it as a universal principle).
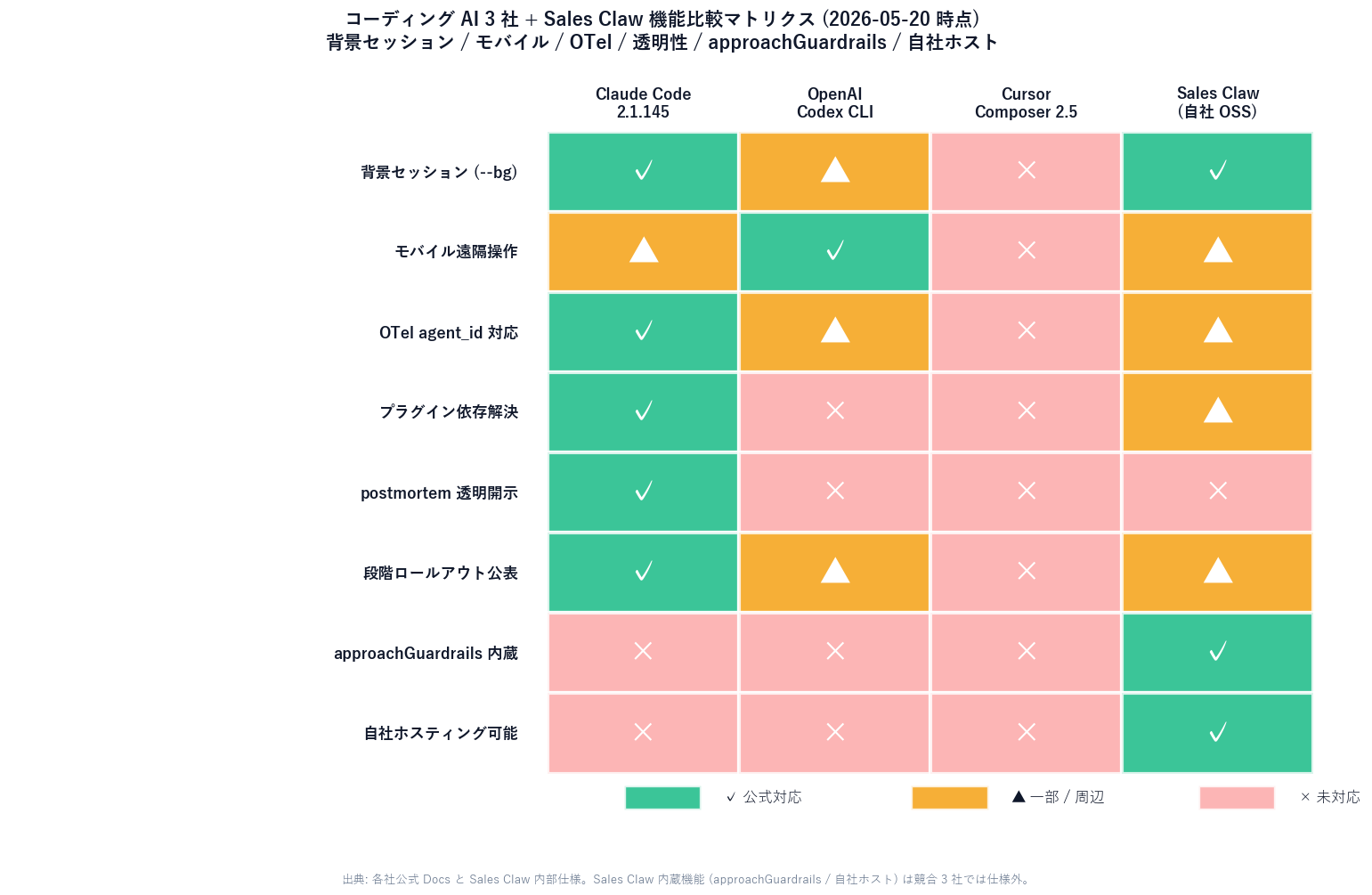
[Author's view] Sales Claw runs three categories of system prompt internally:
We are going to grep all three for "be concise"-type instructions in light of the Anthropic postmortem. Anything that touches reasoning will be rephrased as a final-output-format instruction.
[Author's view] Sales Claw also runs parallel subagents (form-submission worker, approachGuardrails judge, audit-log writer). Following Claude Code's lead, we will add agent_id / parent_agent_id to our OTel spans. That makes the following visible:
This is planned for Sales Claw's next minor release.
[Author's view] Aligning with Codex mobile and Claude Code background sessions, we are promoting Sales Claw's "overnight auto-run + morning approval" flow to an official operation pattern:
The goal is "human-touch time per day is 5 minutes (approval only)." This aligns Sales Claw with the three coding-AI vendors' direction and codifies a standard "infrastructure-era" UI for AI sales automation.
Reading the Japanese-language original? こちら.
本記事は X 公式アカウントと公式ドキュメントを一次情報として参照しています。
この記事の著者
中澤 圭志
Sales Claw maintainer
Designs and develops Sales Claw. Writes from the field on B2B sales automation and applied AI.

