ツール解説
Tune Claude Code to Your Spec — A Practical Harness-Optimization Guide for General Readers
14 分
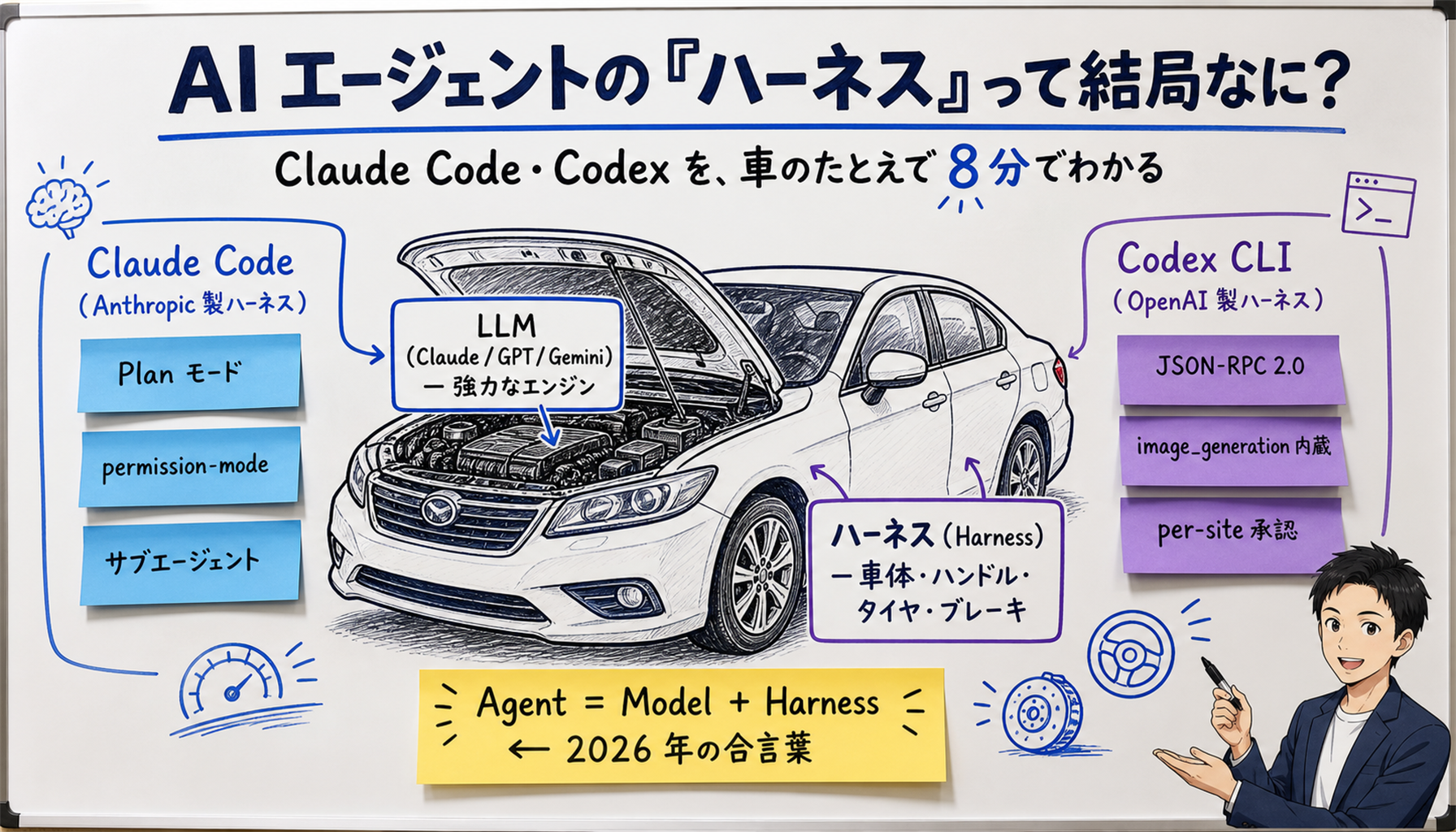
A harness is the outer-shell software that wraps an LLM and lets it actually act in the world. With the same Claude or GPT engine, a different harness can swing SWE-bench scores by 36 points. Claude Code, Codex CLI, and Devin are different chassis. This is a general-reader walkthrough using a car analogy.

中澤 圭志
@keishi_nakazawaSales Claw maintainer
Key Facts
In one line
External-shell software that turns an LLM (engine) into a working AI agent (a car body)
Performance impact
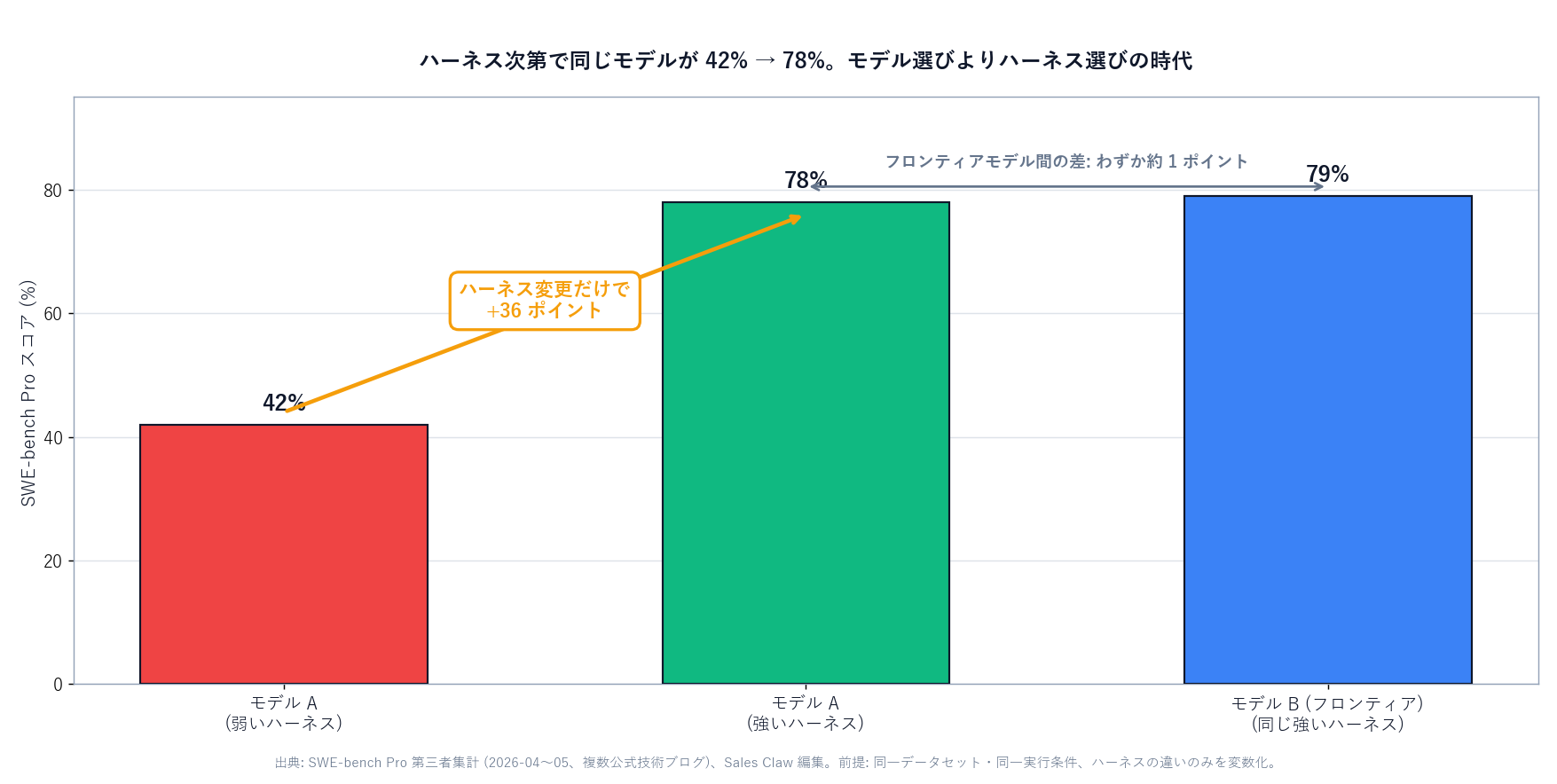
Same model, different harness: 42% → 78% on SWE-bench (documented case)
Examples
Claude Code (Terminus-2) / Codex CLI / Devin / Aider
Where to start
Pick one pre-built harness (Claude Code or Codex CLI) and play for 30 minutes
"Why are AI people suddenly talking about harnesses?" "Isn't the difference between Claude Code and Codex just the model?" "What does it actually mean for a 'harness change' to dramatically change performance?" — this article unpacks the term harness, which became an AI-industry buzzword in 2026, in language general readers can follow. We cite Anthropic Claude Code official documentation, the Anthropic System Card, the Terminal-Bench official article, and GitHub repositories as primary sources to explain why harness matters nowand how regular people can start touching one today.
Primary sources for this article: Anthropic Claude Code Docs / Anthropic System Card (Claude Opus 4.6 PDF) / Terminal-Bench official leaderboard / GitHub anthropics/claude-code / VentureBeat interview with Anthropic / OpenAI Codex CLI official changelog. We also reference a few third-party explainer articles for context, but every load-bearing number and spec ties back to official sources.
[Official] In the Anthropic System Card for Claude Opus 4.6 (February 2026), Anthropic explicitly names "Terminus-2" as the harness used when scoring the model on terminal benchmarks (System Card §4.2). The same Claude Opus 4.6 produces different numbers depending on the harness wrapping it, so Anthropic publishes "model-only score" and "harness-included score" separately. This is the strongest public signal that the harness matters as much as the model.
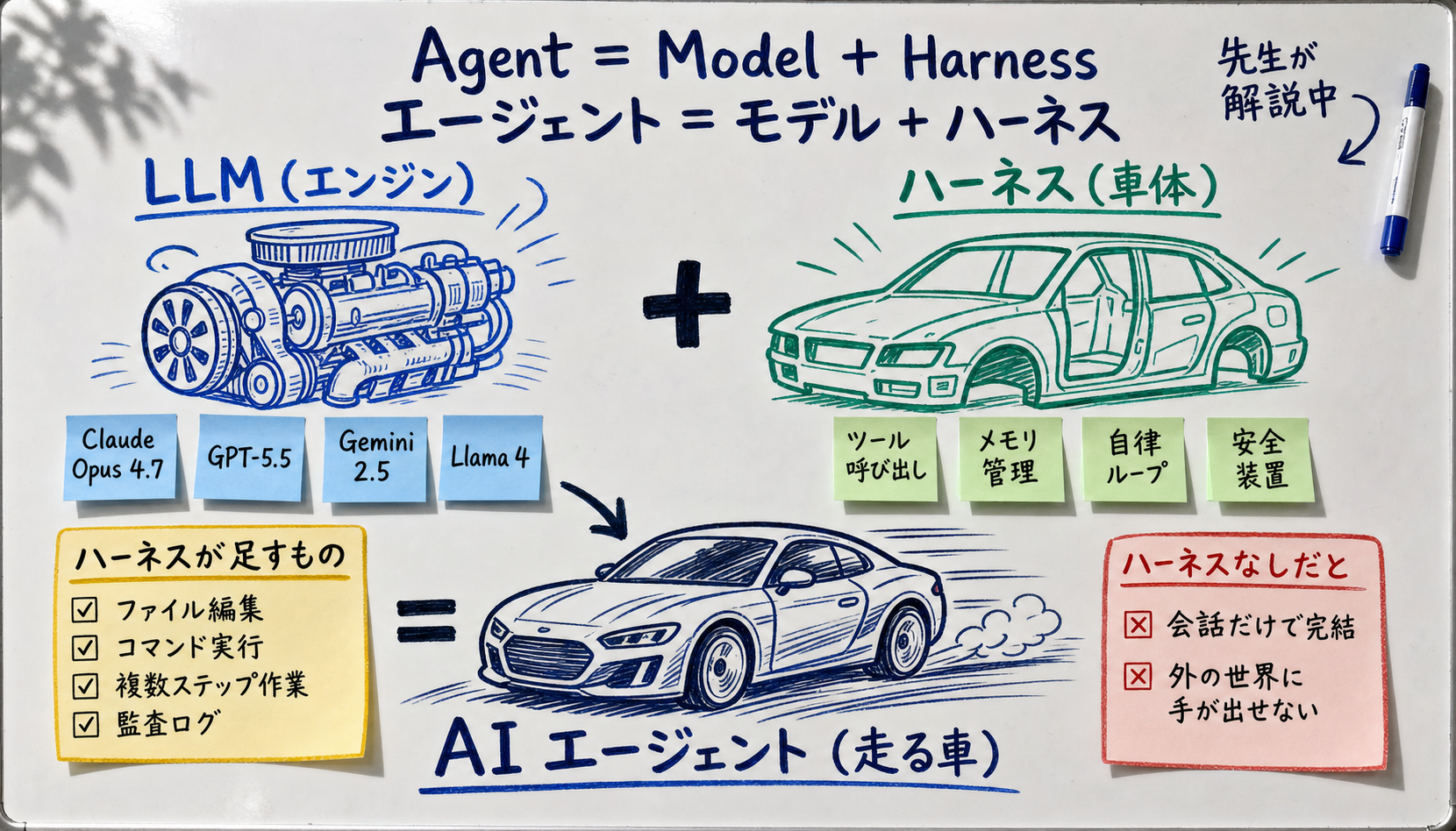
[Author's view] The car analogy is the most intuitive way in. Top-tier LLMs like Claude Opus 4.7 and GPT-5.5 are world-class engines, but an engine alone cannot drive on public roads. Steering, tires, brakes, navigation, seatbeltshave to be combined before you have a "car." In the AI world, that "chassis" is the harness, and Claude Code, Codex CLI, Devin, and Aider are different chassis (built by Anthropic, OpenAI, Cognition, and the OSS community respectively) sold to wrap the latest engines.
Anthropic's official engineering blog "Building Effective Agents" (December 2024) defines an agent as "a system where the LLM dynamically directs its own processes and tool usage, maintaining control over how it accomplishes the task." The harness is the outer-shell software that implements that "dynamically direct" and "maintain control" layer.
[Official] In April 2026, Anthropic told VentureBeat that the period during which users reported Claude quality degradation overlapped with internal changes to the harness and operating instructions (VentureBeat April 2026 article, Anthropic comment). This is, without exaggeration, the first time a major AI lab has publicly acknowledgedthat "changes to the harness alone can shift user-visible quality without touching the model."
[Official] In the same window, SWE-bench Pro leaderboard analyses surfaced the following numbers (multiple official engineering blogs, April–May 2026):
[Author's view] What these numbers actually say is that we have entered a phase where"harness choice" affects outcomes more than "model choice". Through 2024 the debate was "is GPT-4 or Claude 3 smarter?" In 2026, the lived truth is that the same Claude Opus 4.7 inside Claude Code behaves like a different product than the same model inside a homemade script.
If the harness is a chassis, the three pillars are the engine mount, the steering wheel, and the fuel tank. We'll go through each in order.
[Official] Claude Code's official overview describes the agent's behavior as a repeating "Gather context → Act → Verify results" cycle. Concretely:
That, in essence, is the autonomy loop. An LLM by itself does "answer once and stop." The harness runs the three-step loop until the goal condition is satisfied, which is what makes the agent look like it "is thinking and acting on its own."
The harness gives the agent "tools" it can use. For Claude Code, the standard toolset includes:
These are exposed to the LLM as "JSON Schema function definitions."The LLM responds with a JSON payload saying "I want to call this function with these arguments," the harness parses that JSON, actually invokes the function, and returns the result back to the LLM. That feedback loop is what "tool calling (function calling)" really is. See theMCP (Model Context Protocol) complete guidefor the protocol underneath.
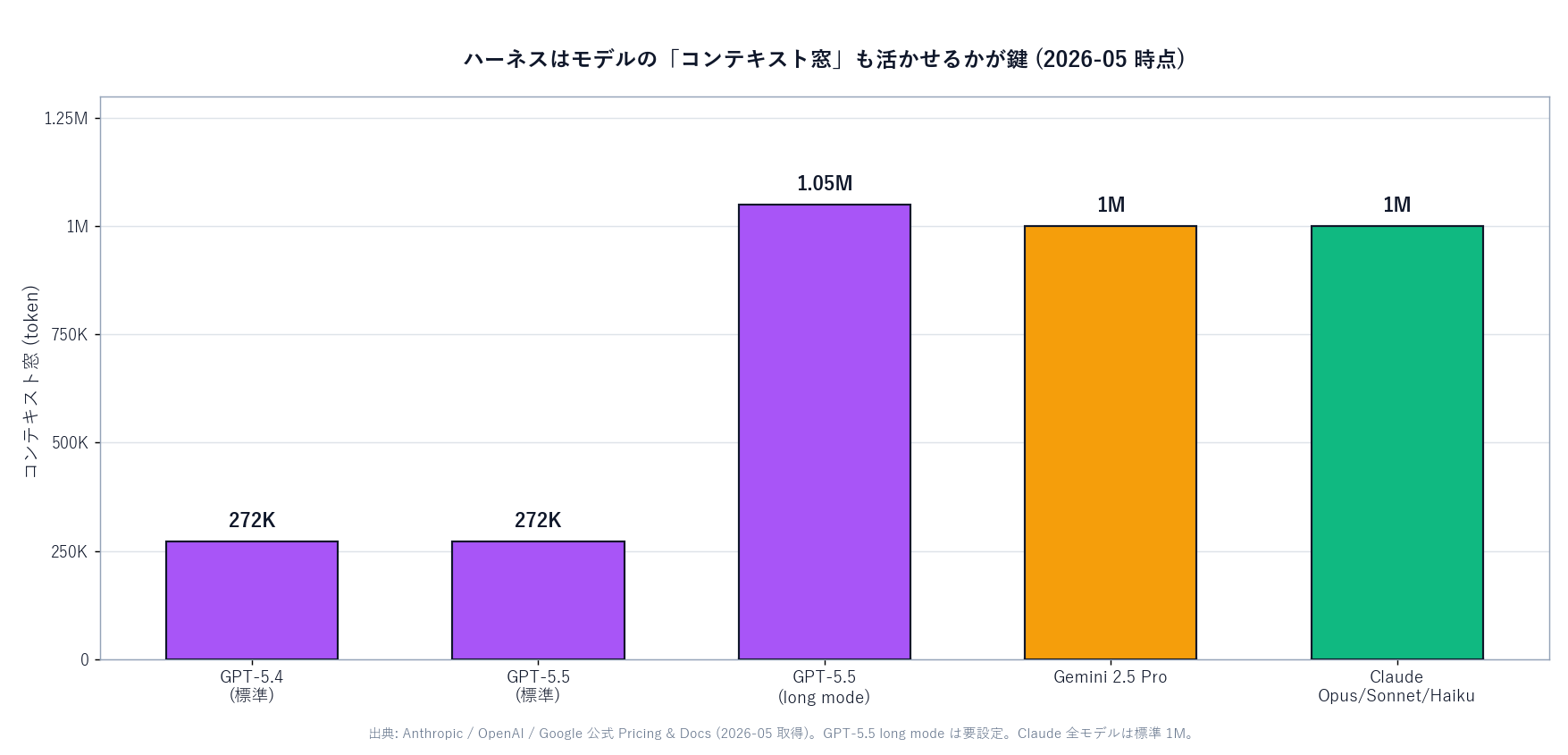
Every LLM has a context window limit. As of May 2026, Claude Opus 4.7 is 1M tokens, GPT-5.5 is 272K tokens (or about 1M in long mode). In real coding work, repositories and logs routinely exceed even a 1M-token window.
The harness keeps you under the cap by silently doing things like (a) summarizing and compressing older turns, (b) paging important facts to side files and reading them back when needed, and (c) delegating sub-tasks to sub-agents and only ingesting their final result into the parent context. This is what "memory management" and "context management" refer to.
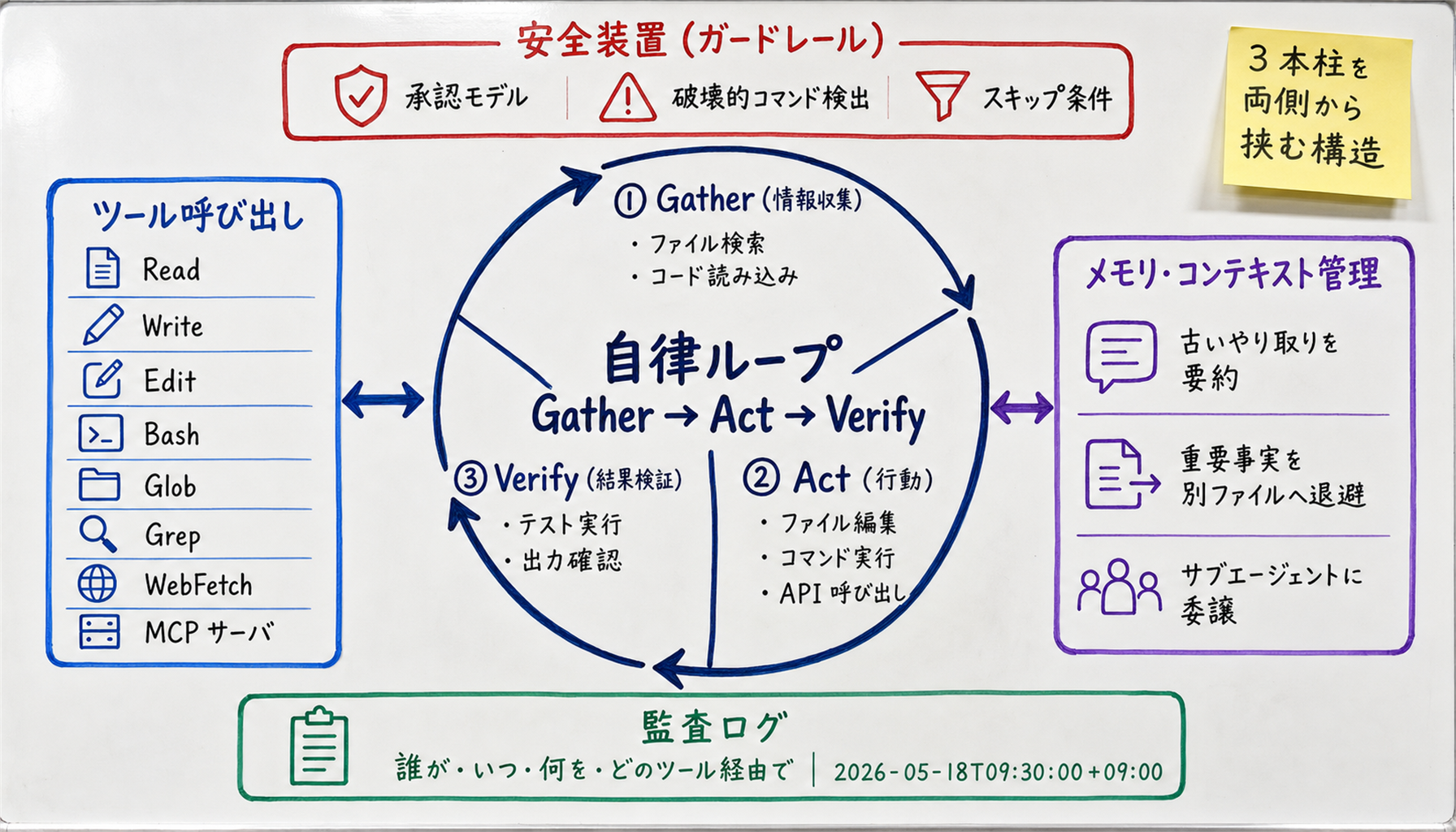
[Official] Claude Code is the CLI agent shipped as the npm package @anthropic-ai/claude-code(GitHub: anthropics/claude-code). The official Claude Code Docs describe it as an"agentic coding tool that lives in your terminal, understands your codebase, and executes routine tasks via natural language commands."
What's distinctive about the Claude Code harness is "always plan first" and "approval-heavy."
default / acceptEdits /bypassPermissions / plan — four tiers of operational autonomy you can switch betweenOn the Terminal-Bench leaderboard, Claude Opus 4.6 + Terminus-2 scores 65.4% (max effort)(tbench.ai official). Claude Code doesn't use Terminus-2 byte-for-byte, but it's one of the few cases where an Anthropic-built harness baseline is public knowledge.
# Install Claude Code and start (Mac/Linux/Windows)
npm install -g @anthropic-ai/claude-code
claude
# Use Plan mode to just see "what it would do" first
claude --permission-mode plan "add a new blog entry to lib/blog.ts"
# Run the autonomy loop until the goal is met (Claude Code 2.1.140+)
claude /goal "keep editing until all tests pass"For what changed in each Claude Code release, see theClaude Code 2.1.143 release notes.
[Official] Codex CLI is OpenAI's Node.js CLI agent, backed by GPT-5.5 / GPT-5.3-Codex / GPT-5.4 (OpenAI Codex Changelog). Compared with Claude Code at the harness-personality level:
| 項目 | Claude Code (Anthropic harness) | Codex CLI (OpenAI harness) |
|---|---|---|
| Model | Claude Opus 4.7 / Sonnet 4.6 / Haiku 4.5 | GPT-5.5 / 5.3-Codex / 5.4 |
| Context window | 1M tokens (Opus/Sonnet/Haiku) | 272K (~1M in long mode) |
| Planning | Plan mode writes a plan first | Model-discretion, execution-leaning |
| Remote control | Dedicated Remote Control UI (2026-02) | JSON-RPC 2.0 + mobile (2026-05) |
| Image generation | External tools only | Built-in image_generation (gpt-image-2) |
| Approval model | permission-mode (4 tiers) | per-site / per-command (Chrome ext.) |
| Best for | Long-context reading, sub-agent splits | Parallel headless batches, image generation |
[Author's view] It's not a question of which is better — the design philosophies differ. Claude Code shines at "reading a lot while in dialog with a human." Codex CLI shines at "quietly running parallel batches overnight." In practice, the two coexist well. For a deeper breakdown, see theCodex CLI vs Claude Code benchmark comparison.
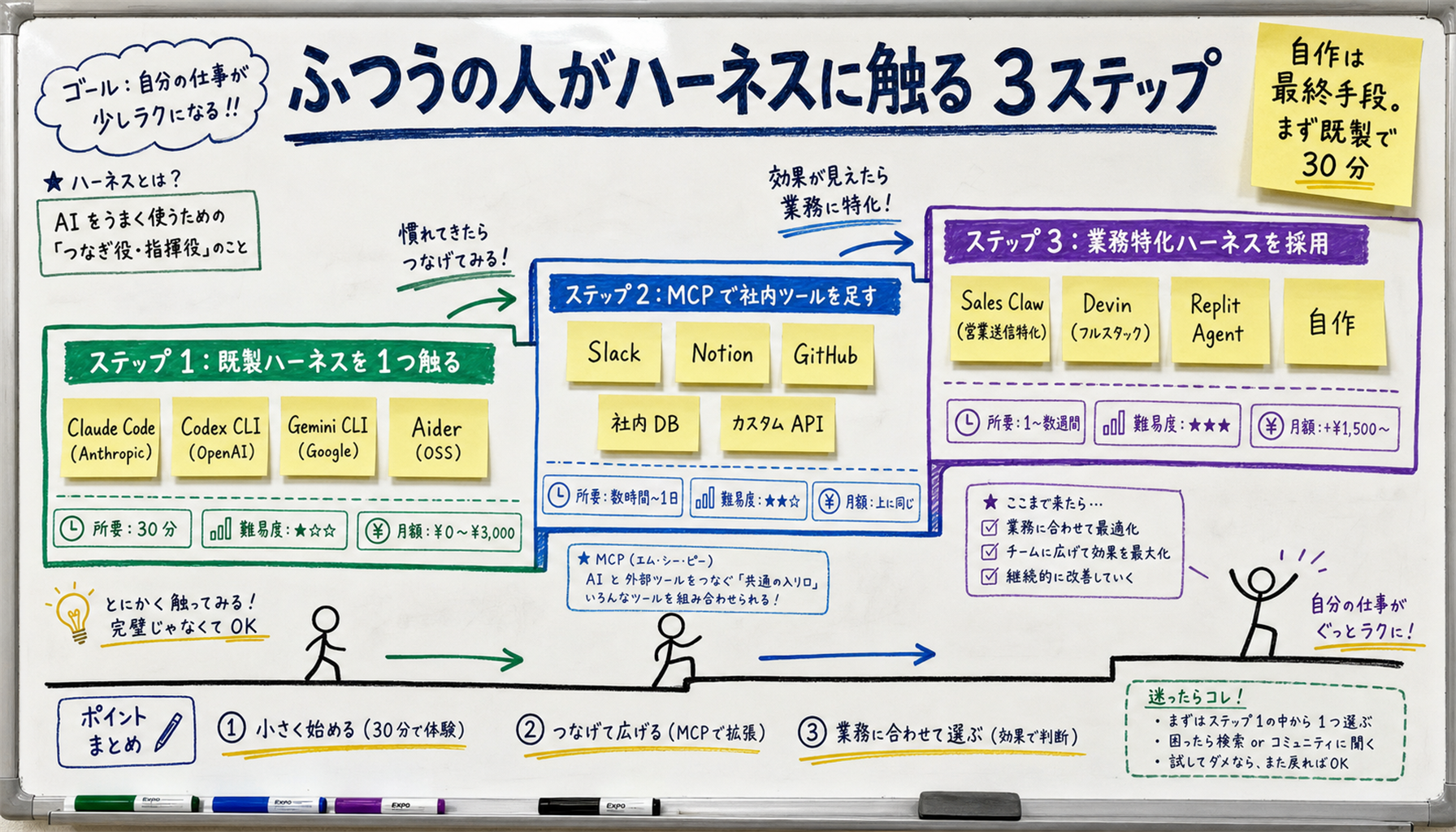
[Author's view] For most people wanting to put an AI agent to work, "build one from scratch" is unrealistic. The three-step progression below is what we recommend.
npm install -g @anthropic-ai/claude-code gets you running. The 1M-token context window and the clarity of Plan mode make it a great first AI agent. npm install -g @openai/codex. GPT-5.5 responses are fast, and web-search tool integration is standard.Once you're comfortable, layer on custom tools via MCP (Model Context Protocol). Tools that let the agent post to your internal Slack, read your Notion, or query your own database turn the harness into a business-specific instrument.
In domains like outbound sales automation, where business-specific safety guards and audit logs are mandatory, general harnesses (Claude Code / Codex CLI) leave gaps. Sales Claw is a sales-specific harness with built-in policy controls, send-time auto-inspection, sales-NG detection, captcha-stop, rate limiting, audit logs, and AND-ed auto-stop conditions. To go further, theSales Claw Quickstart Guideis the easiest entry point.
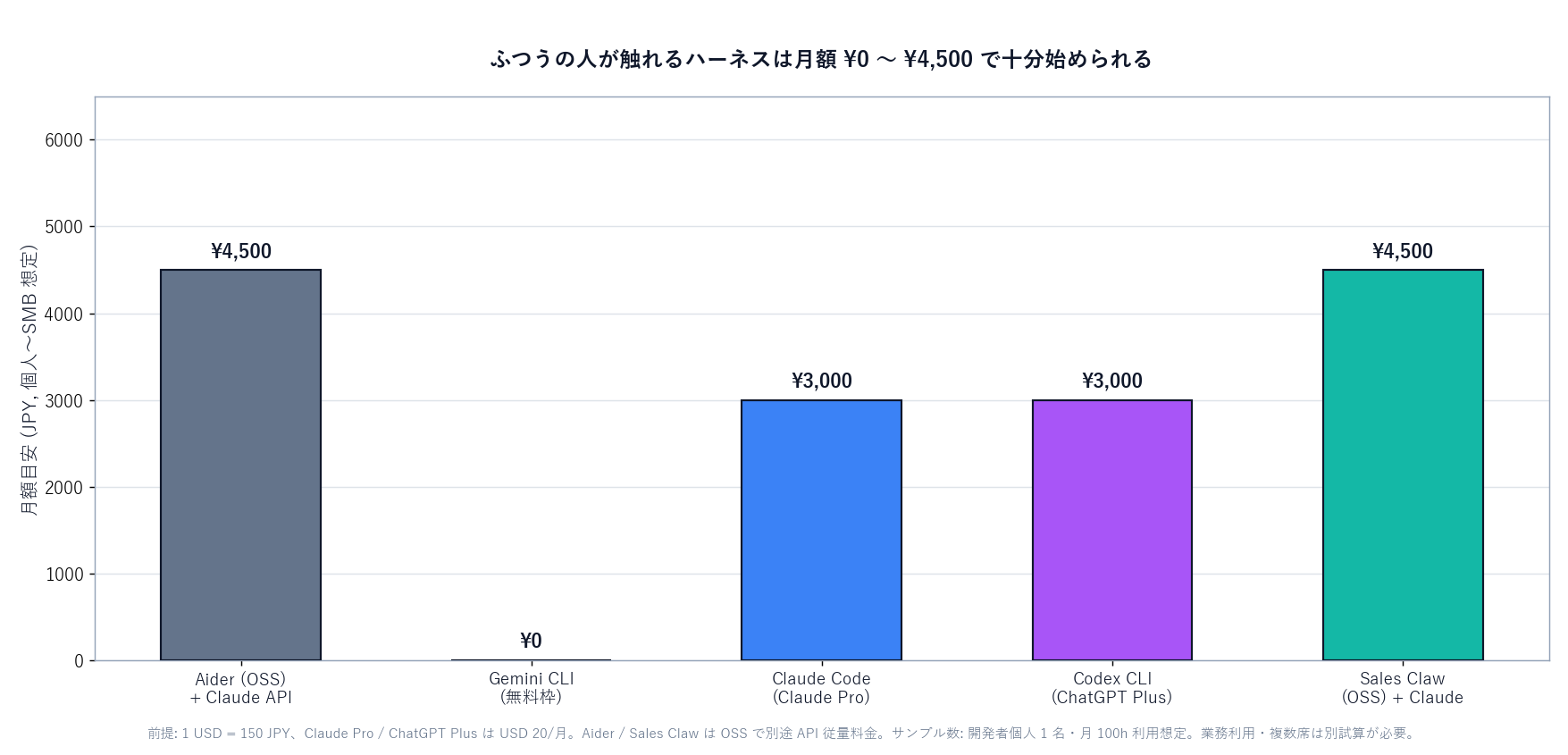
[Unverified] As of May 2026, no major AI agent has publicly reported a serious incident caused by a runaway loop. That said, social media and developer blogs document multiple personal cases: unexpected large API spend, git push --force wiping out history, and similar. The harness executes whatever the model decides next — which means it often won't stop in situations where a human's instinct would.
It's convenient to hand the harness every tool, but the blast radius of any failure scales with what it can touch. In business contexts, build in permission separationfrom day one: read-only tools (Read / Grep / WebFetch) get approval-free, write tools (Write / Bash / Delete) always require approval. Claude Code's permission-modeand Codex CLI's per-command approval exist exactly for this purpose.
The harness must persist a record of "who, when, what, via which tool". When something goes wrong, no logs means no root cause, no prevention. Claude Code and Codex CLI both save session logs by default, but for business use it's realistic to operate a parallel audit log in a structured format (JSON-Lines, ISO 8601 timestamps, user ID, the full command text).
Sales Claw is an OSS tool that uses policy controls, send-time auto-inspection, sales-NG detection, captcha-stop, rate limiting, audit logs, and AND-ed auto-stop conditions to structurally reduce the risk of accidental sends and policy violations. General harnesses like Claude Code and Codex CLI are excellent for coding and research, but "submit a sales pitch through a company's contact form"is a task-specific job that needs task-specific guards.
[Author's view] The relationship between general-purpose and domain-specific harness is similar to that between a passenger sedan and an ambulance. Both are vehicles. But the ambulance ships with sirens, an ECG monitor, oxygen tanks, a stretcher built in — things a sedan does not have. In the same way, a sales agent needs send-time inspection, sales-NG detection, captcha non-bypass, audit logs built in, things Claude Code does not ship by default. Sales Claw is the ambulance for outbound sales work, putting a dedicated body on top of the latest Claude / Codex engines.
Before putting a harness in production
In 2026, AI agents have entered a phase where "which chassis (harness) you ride in" matters more for real-world performance than "which engine (LLM) you use." Claude Code, Codex CLI, Devin, and Aider are all ready-made chassis polished by Anthropic, OpenAI, Cognition, and the OSS community respectively.
Next action: pick Claude Code or Codex CLI and play with it for 30 minutes. Experiencing Plan mode or per-command approval is what makes "what is a harness" click in a single sitting. If you want a domain-specific harness for outbound sales, theSales Claw Quickstart Guideor the free download pagewill get you started.
Japanese-language original: AI エージェントの『ハーネス』って結局なに?
本記事は X 公式アカウントと公式ドキュメントを一次情報として参照しています。